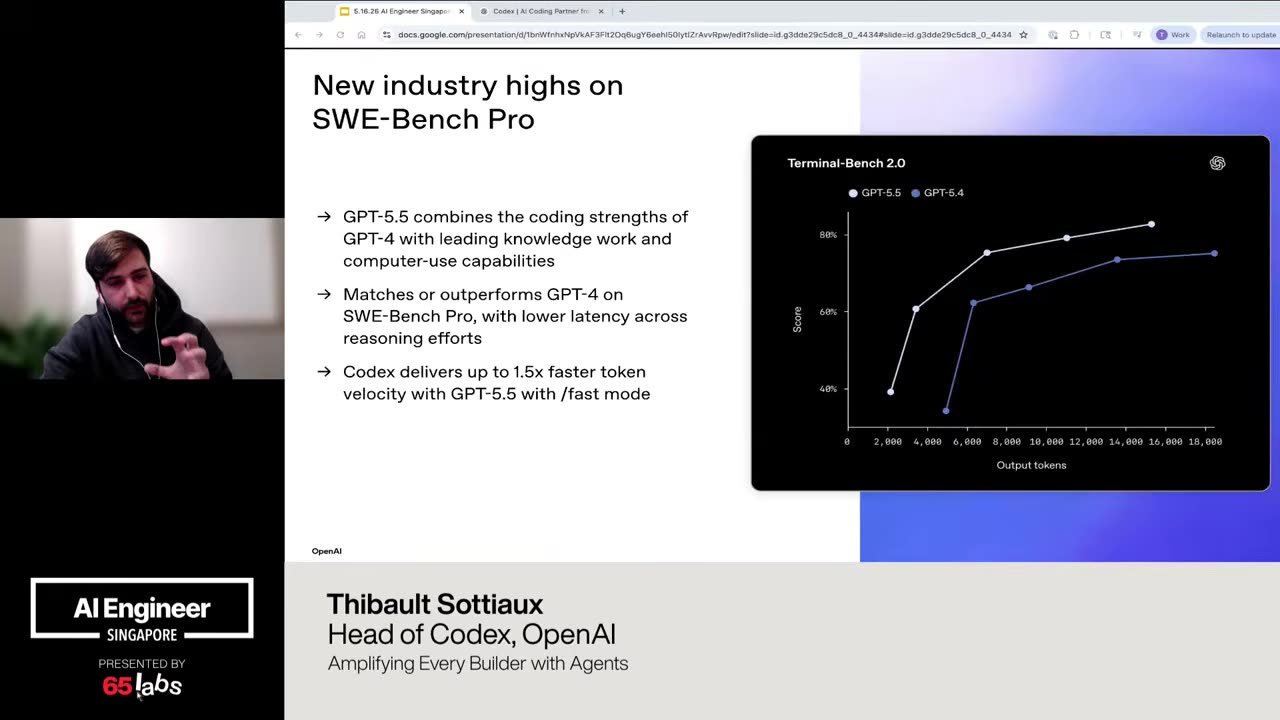
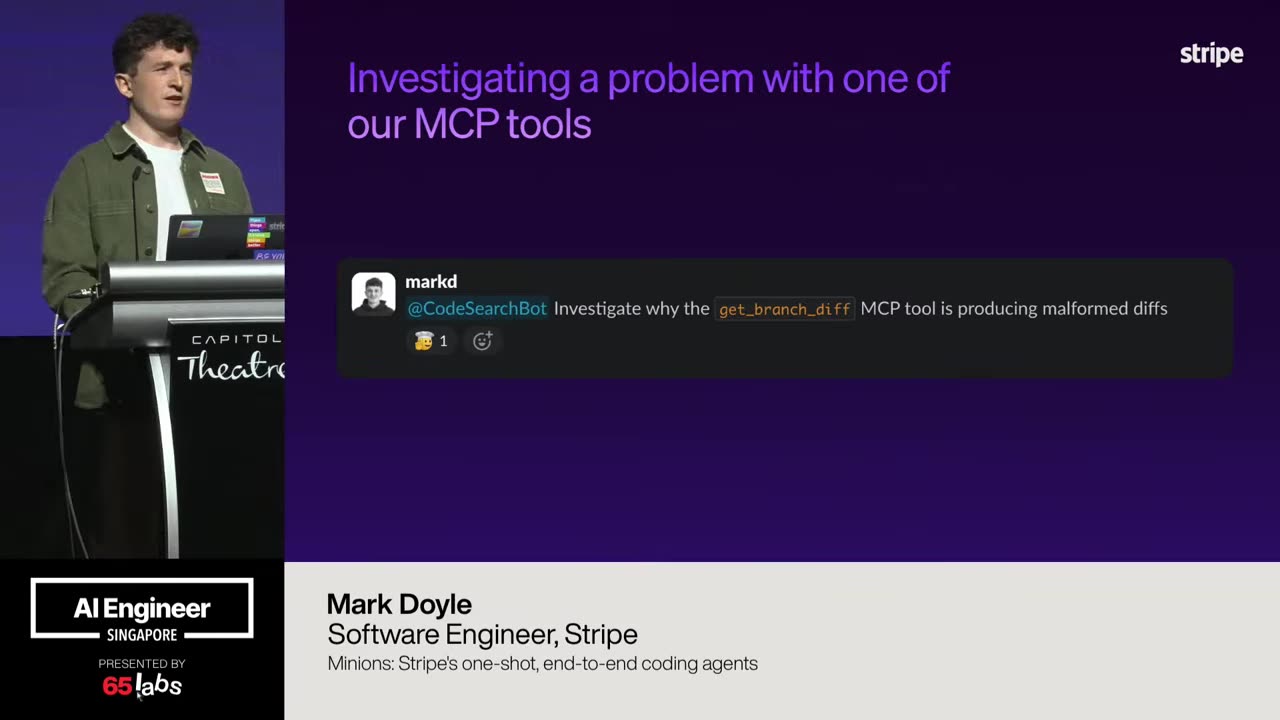
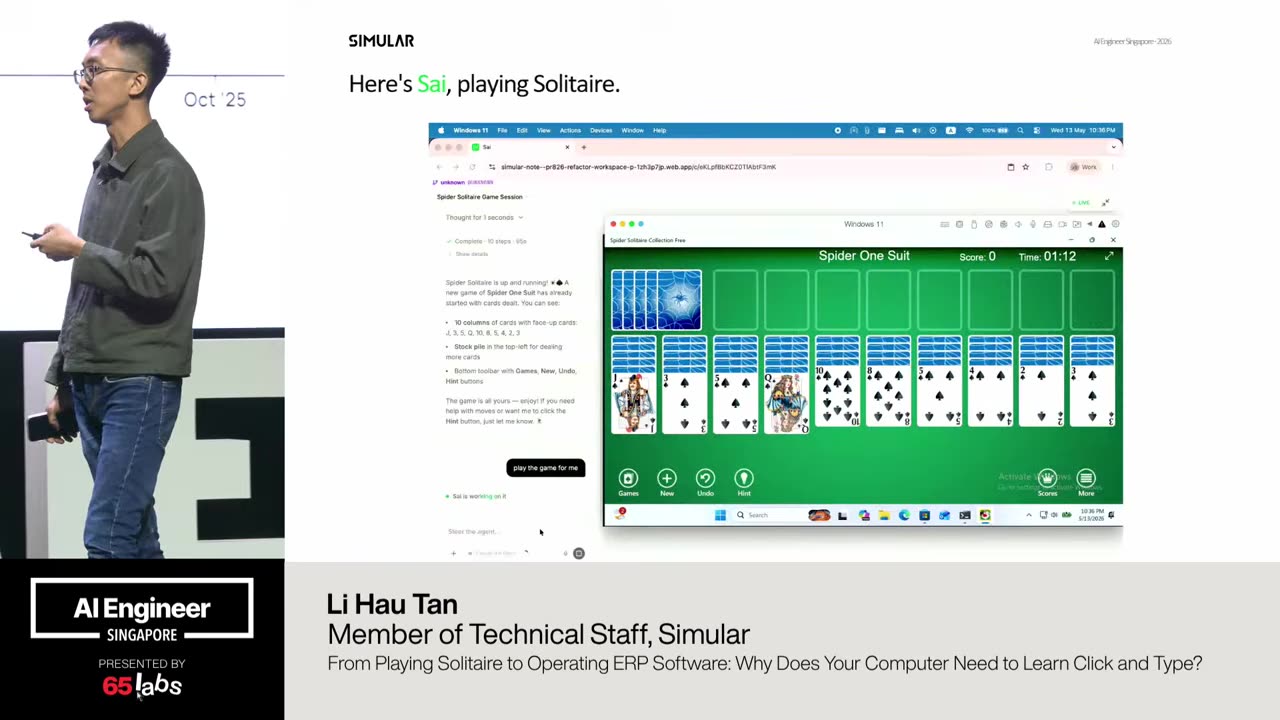
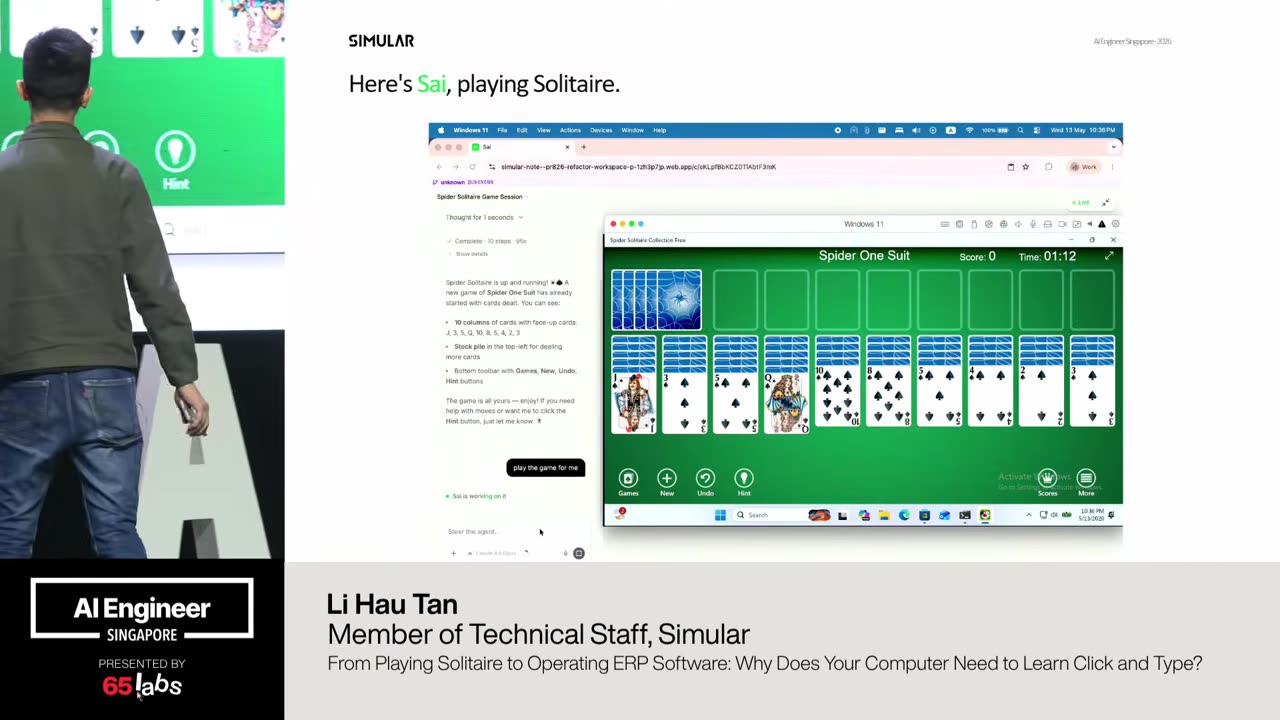
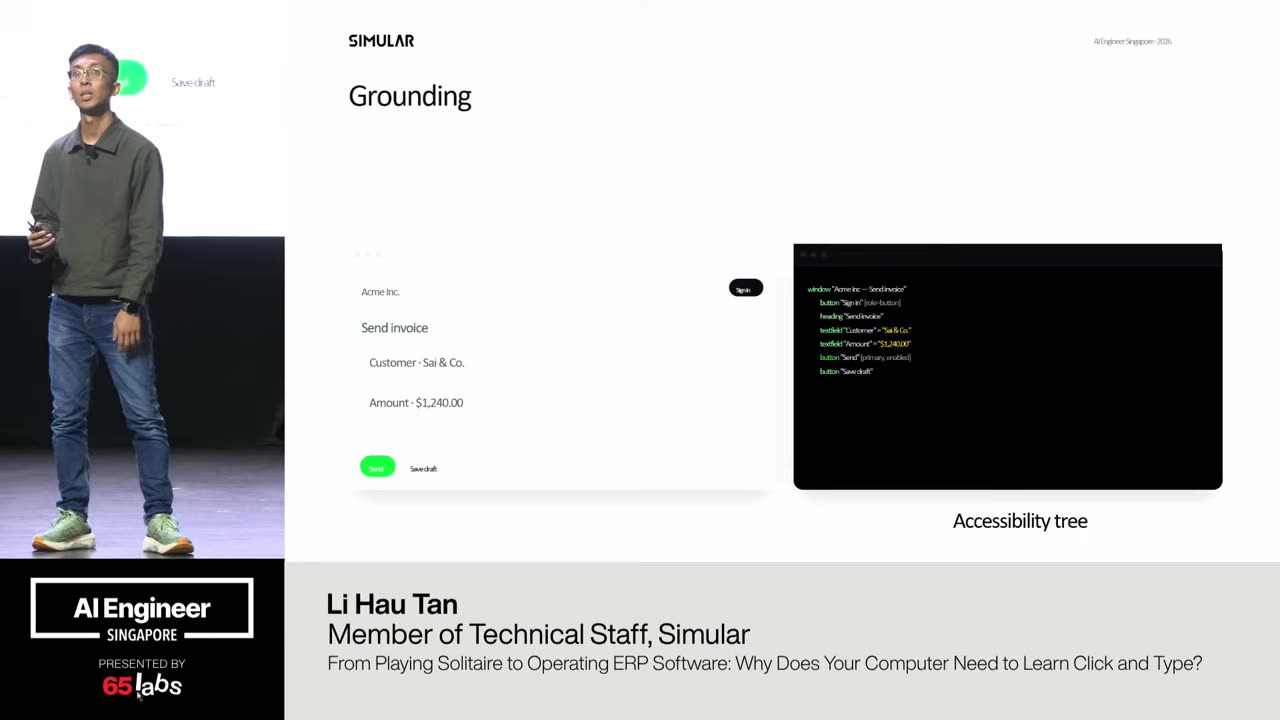
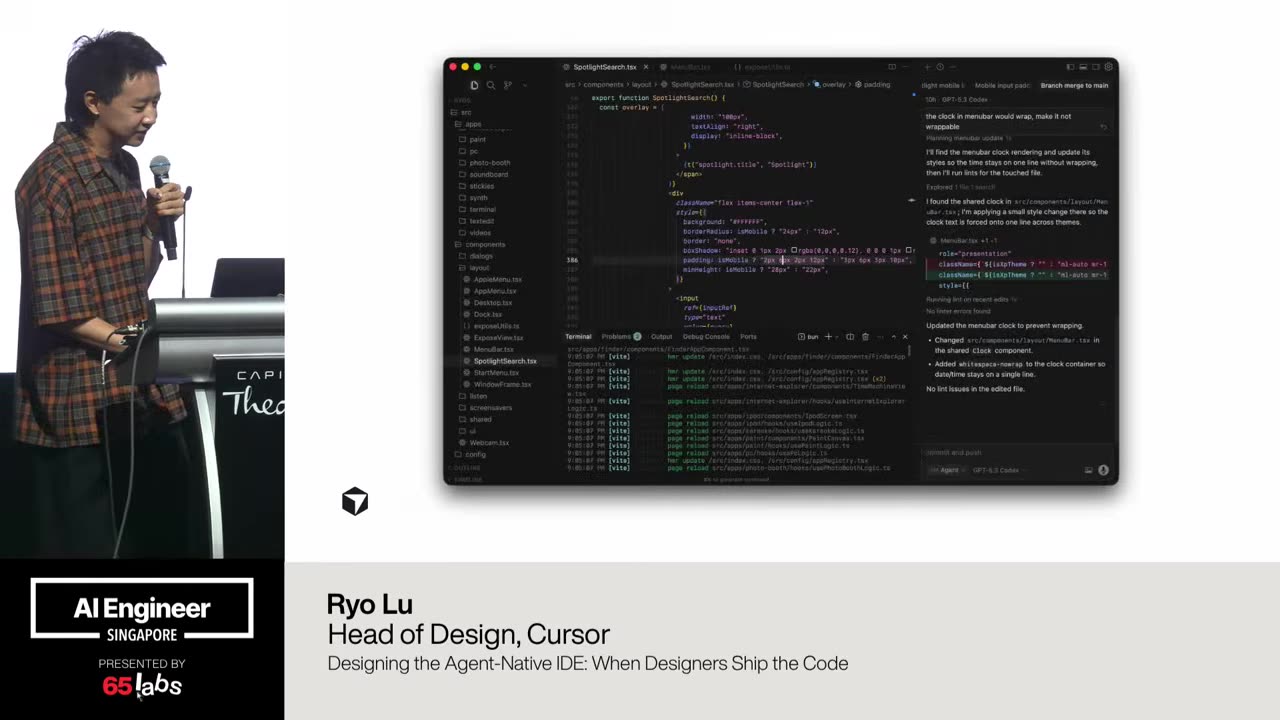
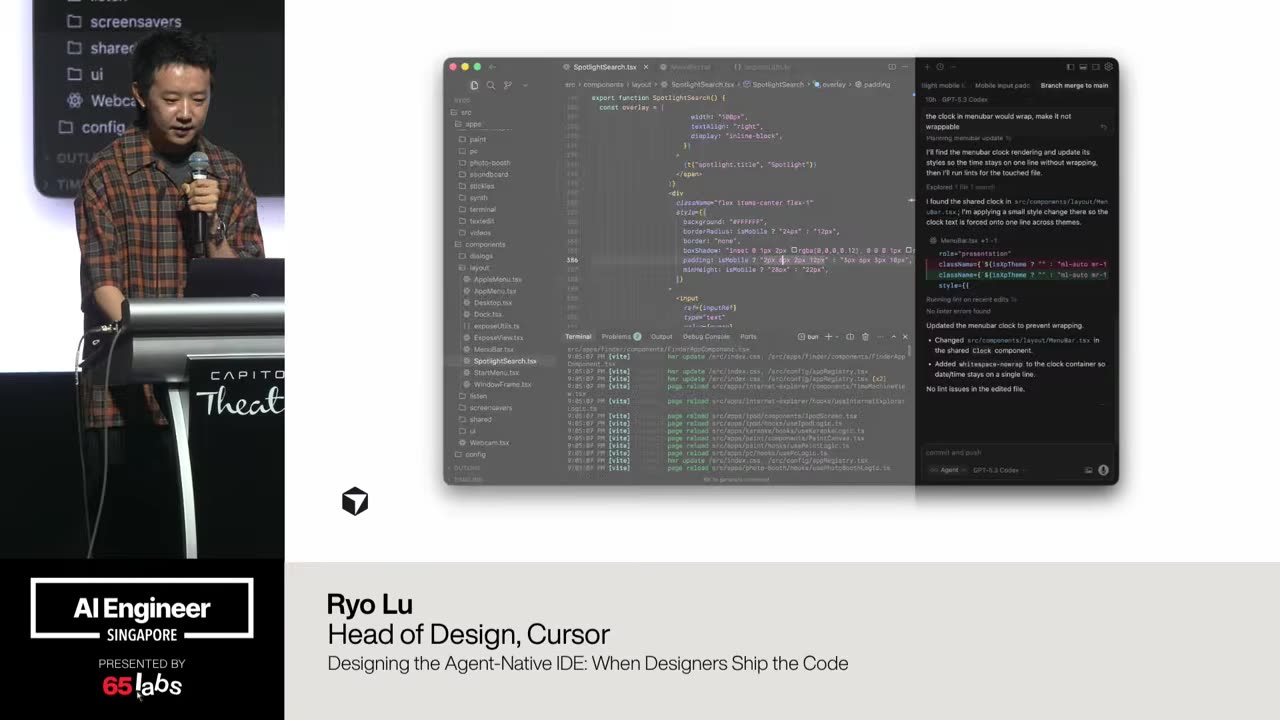
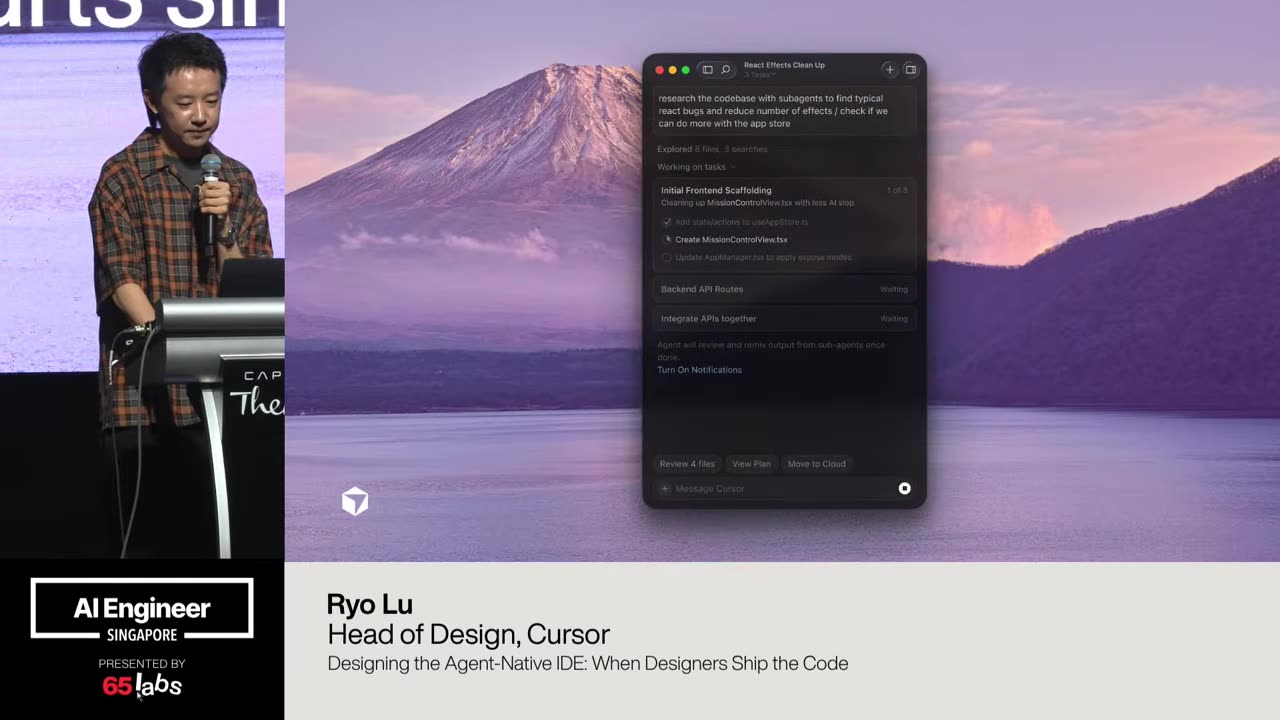
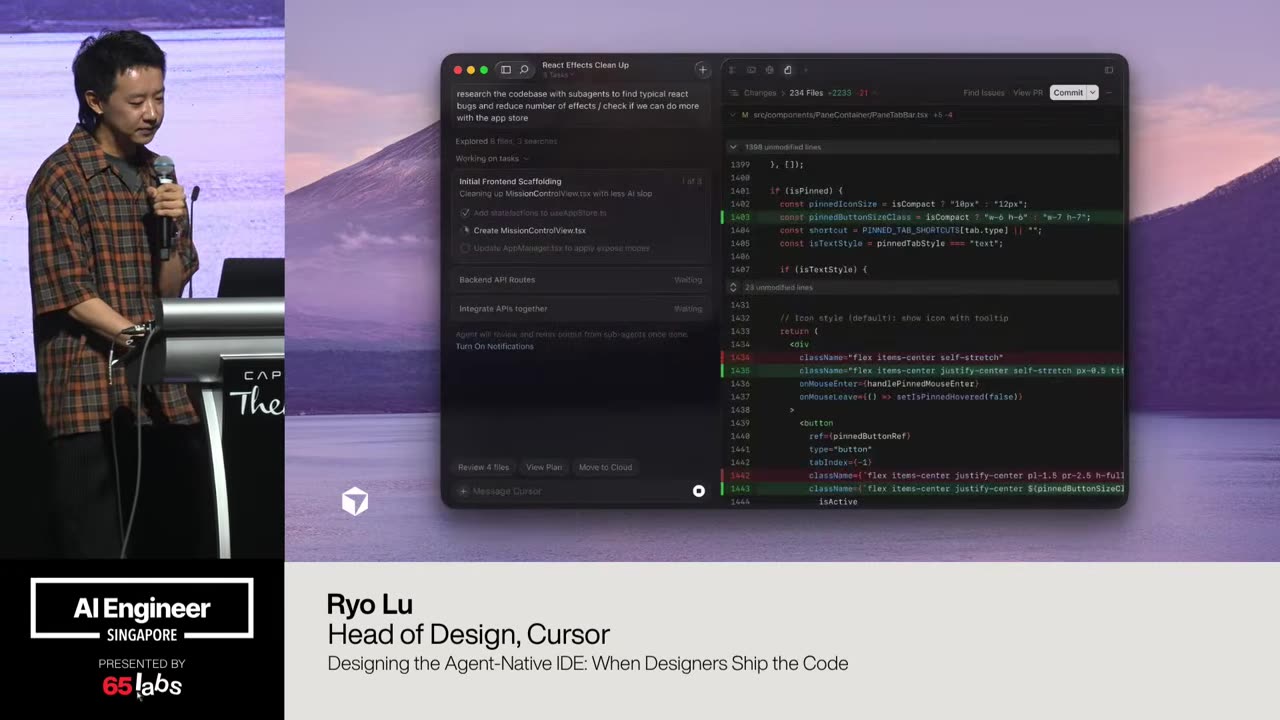
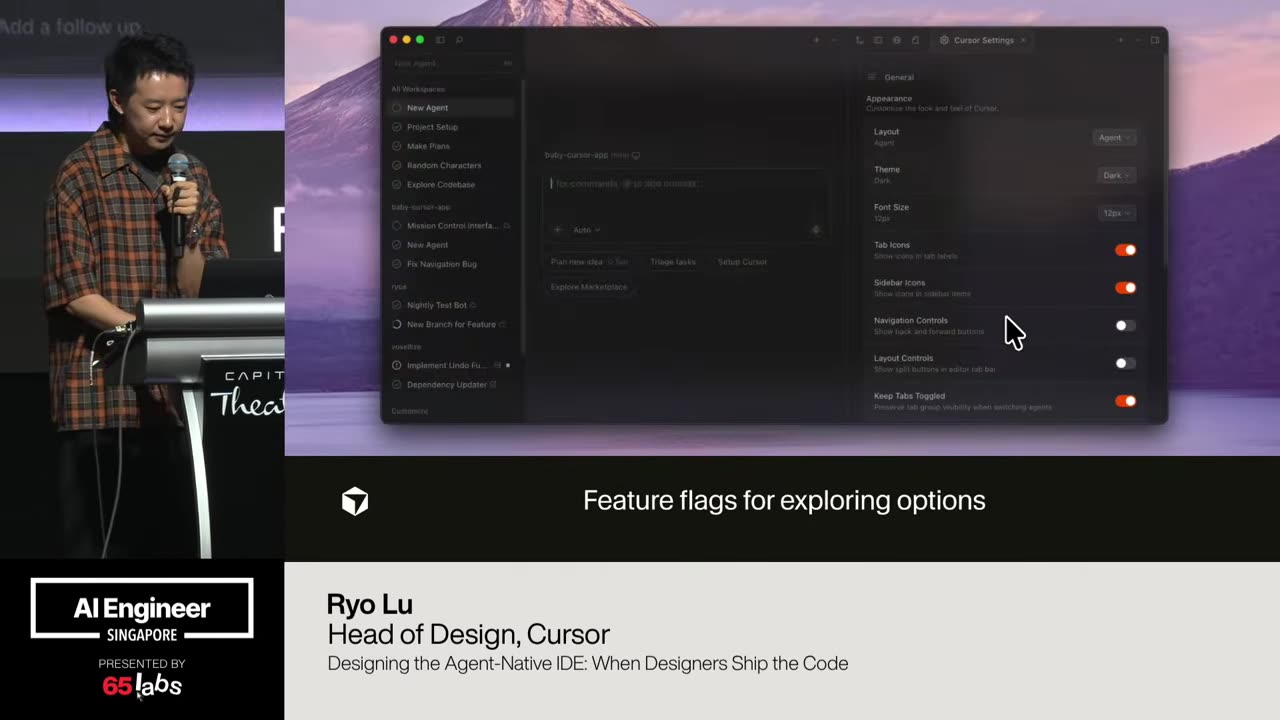
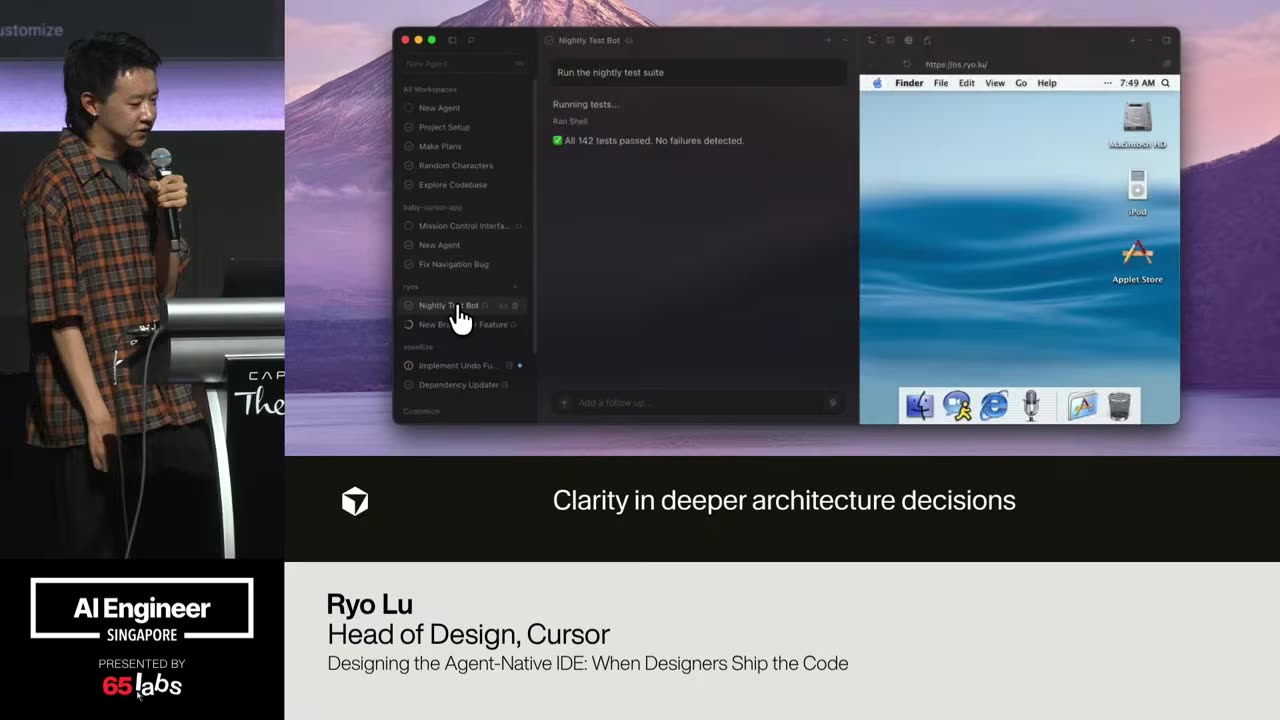
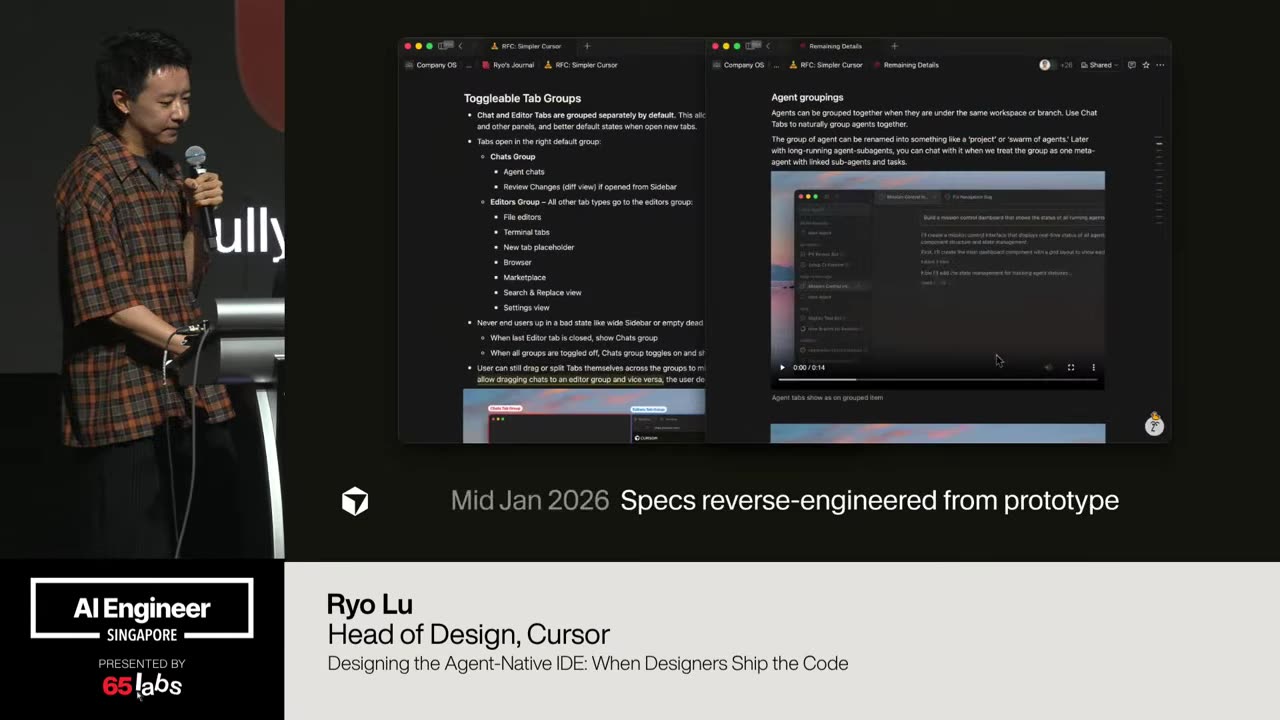
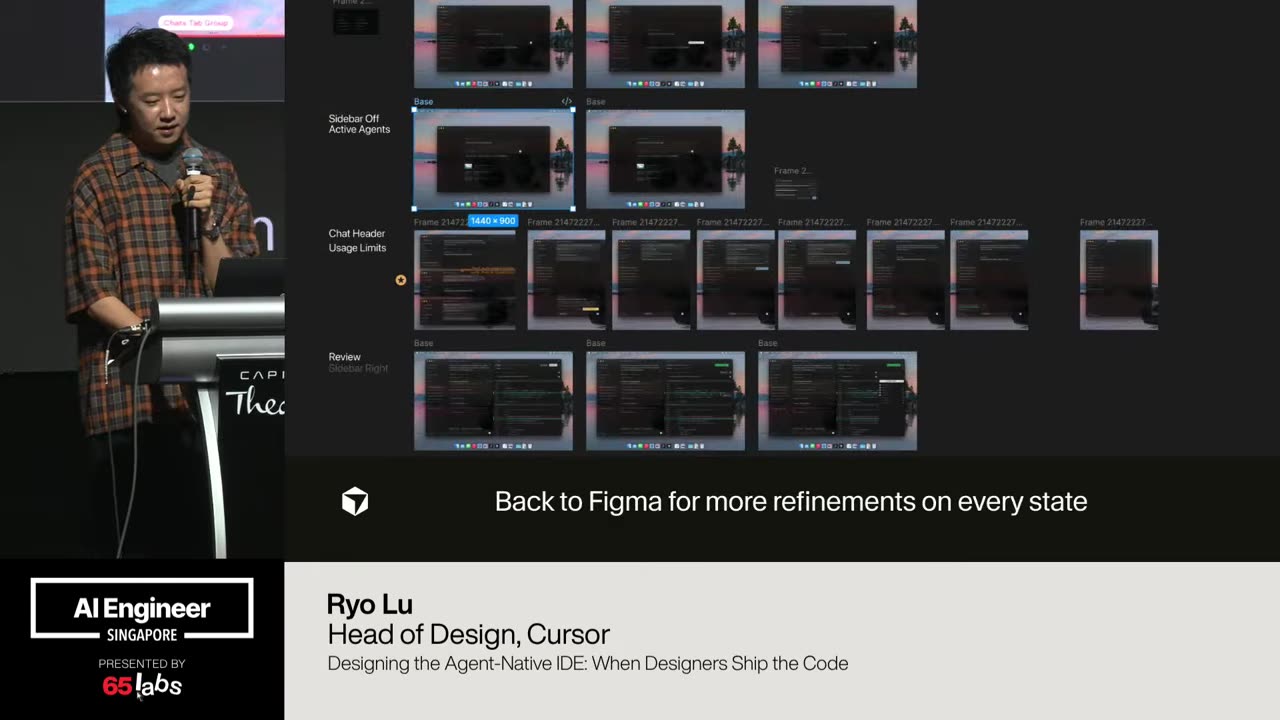
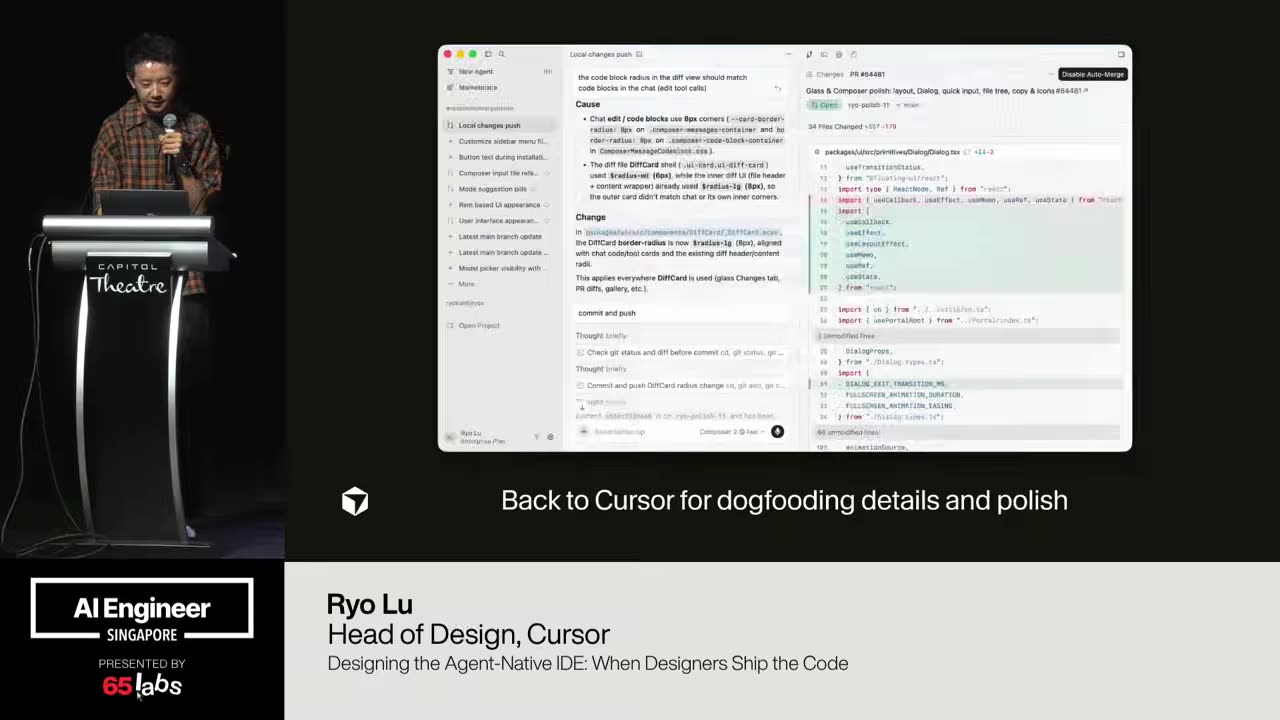
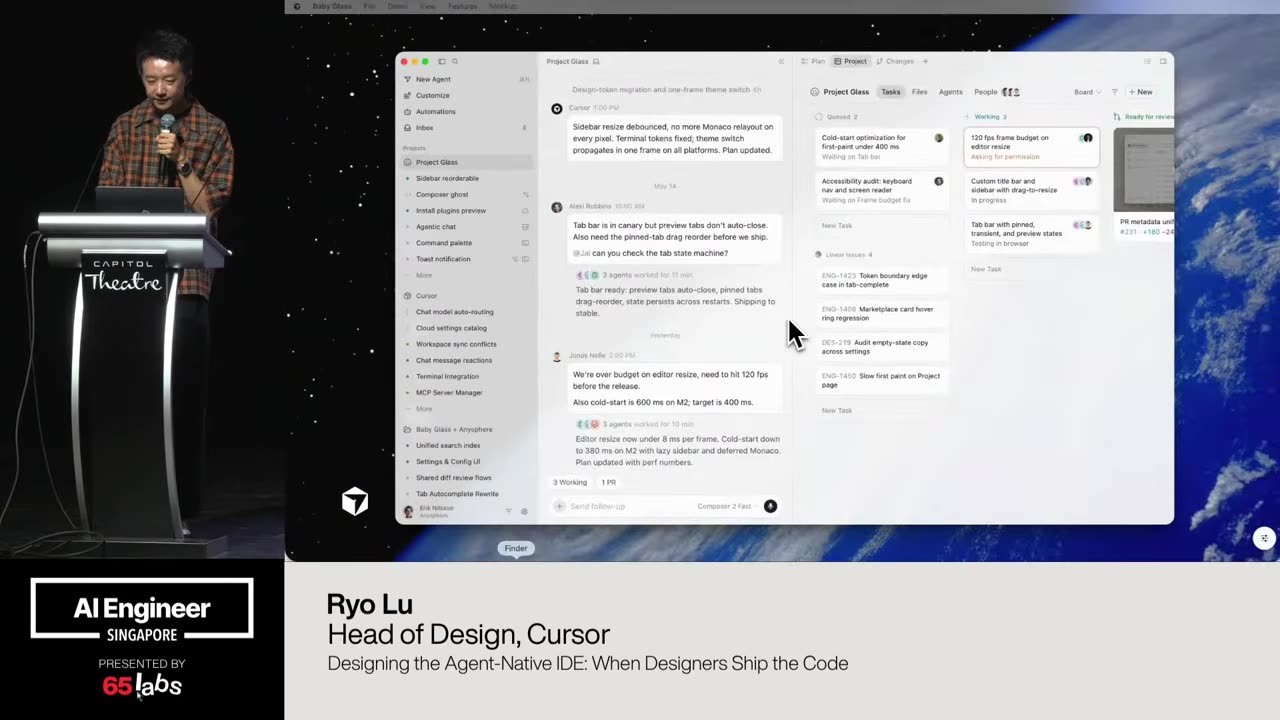
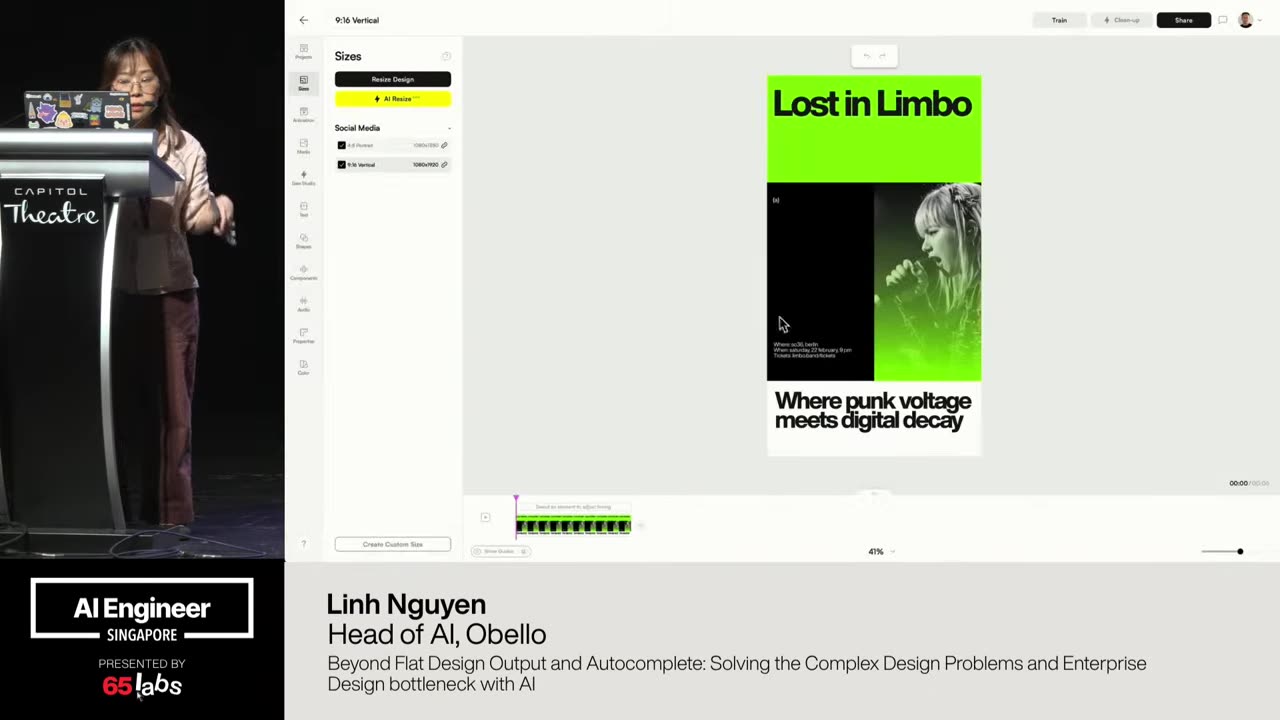
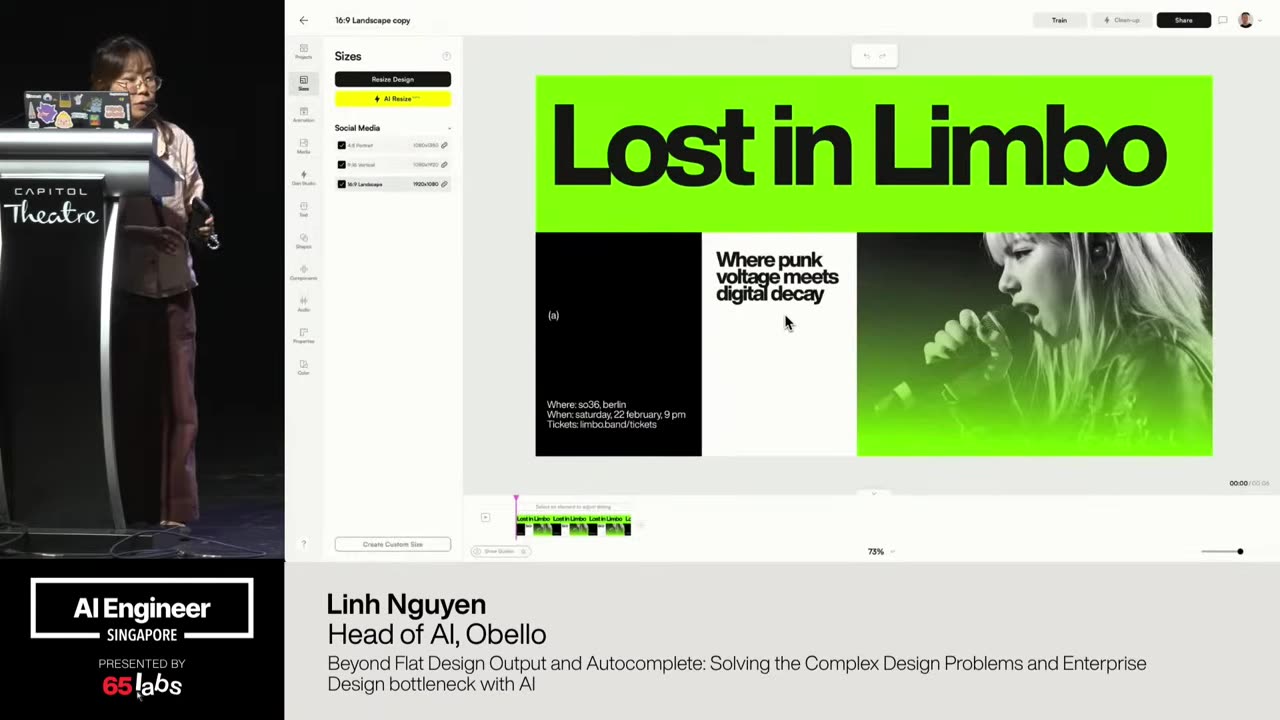
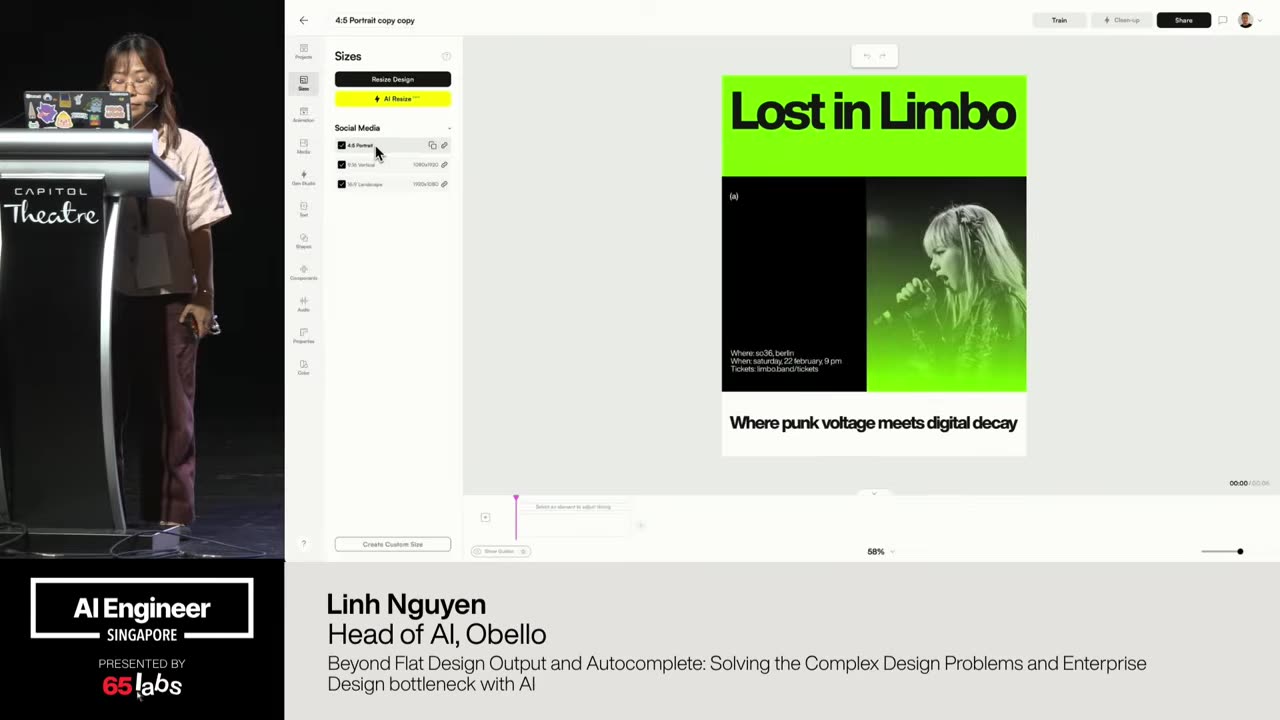
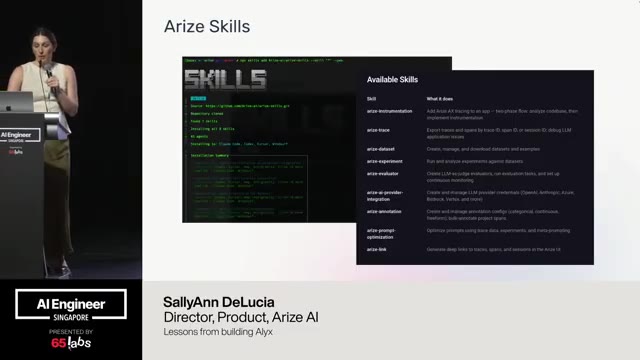
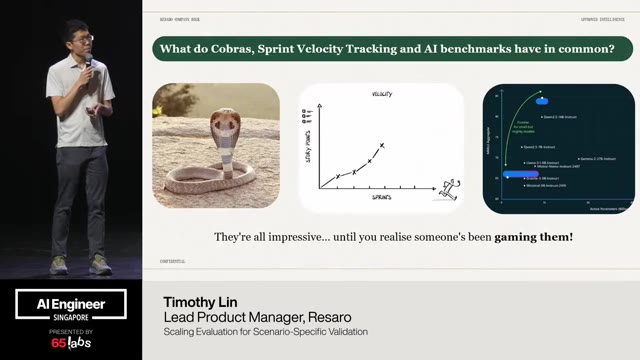
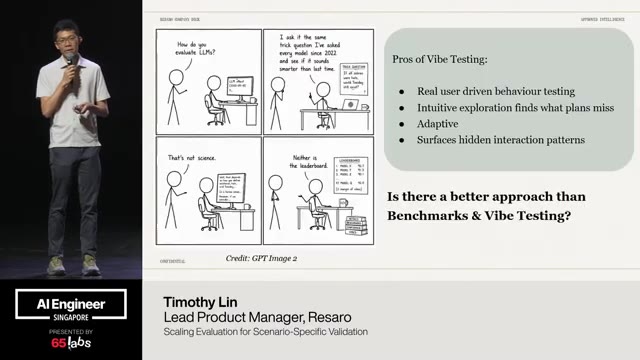
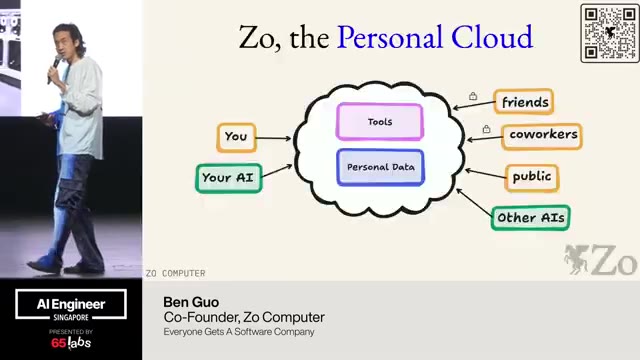
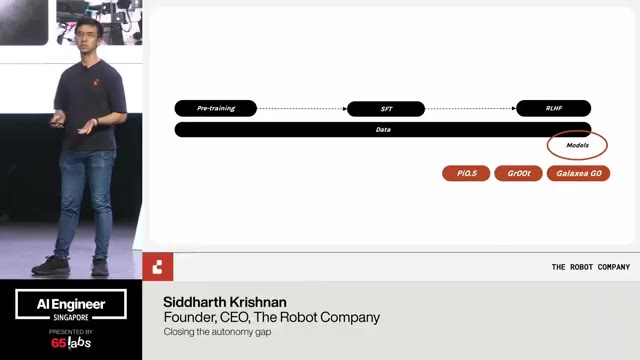
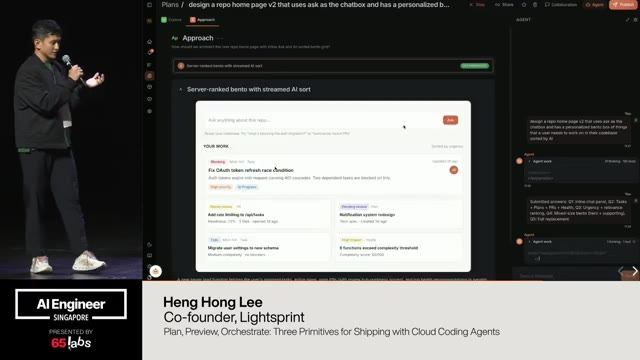
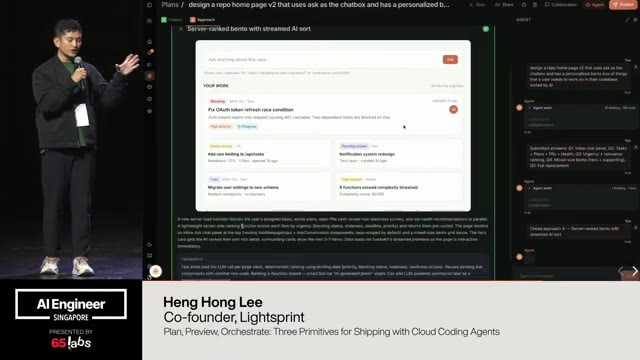
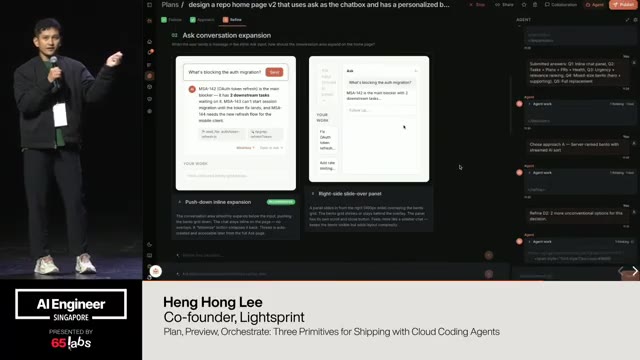
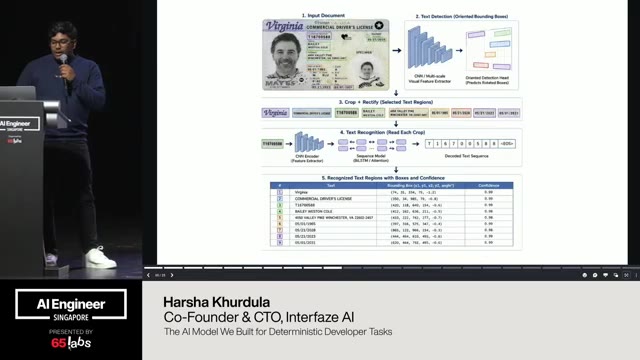
Cool. Hi. Uh, I'm JJ. Uh, I'm a, uh, engineering director at at DeepMind. Um, and so I lead the applied AI team there. Um, I'm based here in Singapore. Um, I am hiring, so if people are curious about, um, working there, um, definitely reach out. Um, so I'm going to talk a little bit today about moving from uh, hackathon kind of things to production, which is sort of what my team does.
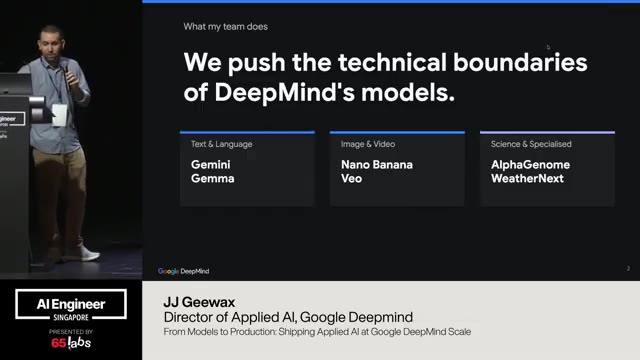
Um, and dealing with models at scale. Um, so before we get into that, I kind of wanted to share a little bit about what my team does. And I see at least one of them here. Hopefully the others are as well. Um, so what we try to do is we push the technical boundaries of the deep mind models. Um this means the ones that I think most of us are familiar with um Gemini and and Gemma which is our openw weight um text model.
Uh but it also includes the nanobano and vio uh video and image models as well as the more sciency things. So that's the alpha genome and uh weather next. Weather next predicts weather and hurricanes and large scale um storms and things like that. So our job is to try to make the models do what they weren't necessarily designed to do or blow past the limits that we might have set on them.
So um a good example with VO is it generates 8 seconds worth of video, right? So you give it a prompt and you get 8 seconds of video out. Um what happens if you wanted to generate like a whole scene from a movie, like five minutes worth? Uh how do you do that? Our team tries to do those sorts of things. Or with Nana Banana.
Let's say that you have a movie and you want to outpaint the whole thing um to make it like widescreen, for example. Um that's kind of an an example of what we might do. Uh these things sound kind of easy because they're just more of the same, but it's actually a much more challenging problem and uh we have to come up with clever ways of getting around it. Um so uh what we ultimately try to do here is make the models do real things.
So, it's nice to have 8 seconds of video, but that's kind of a fun hackathon project. Um, it's not really a real thing. You can't sell that to a movie studio. Um, I can't be like, "Look, here's your 8 seconds of of movie." You need to kind of do more than that. It's also making the model sort of adhere to what your guidelines might be.
Um, describing a movie in text is actually really challenging to get it right and then you end up with this giant prompt and it's very fragile and it breaks. Figuring out how to anchor it off of key frames and understand animation and you know behave the way an animator or a director wants it to is actually a really surprisingly challenging problem. Um so we try to do all of that. Um now I I want to pause for a second because I was just saying how like oh the models aren't good enough.
They only generate 8 seconds of video. I I kind of want to pause and just I need to say this AI stuff is amazing. Like it is completely crazy. I I I don't know if you guys remember, but like a few years ago, like chat GBT didn't exist and our lives were totally different. Um, and there seems to be this world of like the models are incredible and they're still at the same time like not enough.
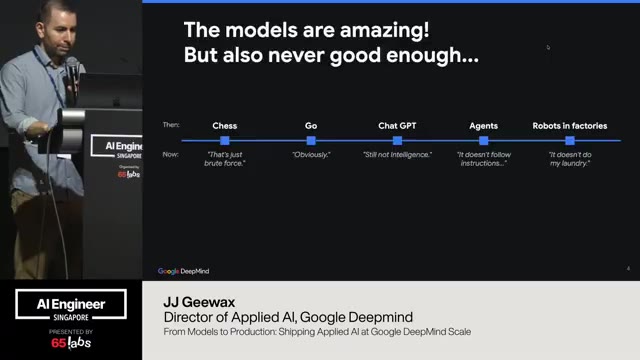
They don't do real things, you know, my whole job. Um, but like there's always been this moving goalpost thing like with chess, right? I don't know if you guys remember when like the whole Deep Blue thing happened. I was a kid so I wasn't really paying attention, but we like computers beat somebody at chess and then everyone was like, "Oh, that's amazing." also, oh, it's just chess.
Um, and then go was was 10 years ago. Uh, Demis just went to Korea to celebrate 10 years of like solving Go. And everyone was like, oh, that'll never happen. I remember I was working at Google at the time and everyone was like, is this going to work? Like, is it going to win? I I don't know. And then it then it did most of the way.
And now everyone's like, oh, it's just go like gh. Um, and then chat GBT came around and it was incredible. I remember showing my wife that she could just ask for, you know, things and it would answer her and like turn it into a table and all kinds of crazy stuff. Like incredible. And now we're like, ah, chat GBT old news.
It's just a chatbot. And and now we're at this sort of weird phase now where like we have agents and they do stuff like they call and make restaurant reservations using like 11 Labs and Open Claw and they're accidentally deleting all our emails and you know, crazy things like this. And it's like we're still mad that the agent doesn't follow our instructions, right? Like just how spoiled we've gotten.
Um, does anybody remember when we got Wi-Fi on airplanes? Like, and that was incredible. And now it's like, uh, it doesn't have Wi-Fi. Like, uh, and now now there's robots and robots are like doing factory jobs and we're like, gh, but it won't even do my laundry. And it's just And I actually saw a video of a robot uh making a bed and taking out the trash.
And so maybe soon this bullet point will go away. So, I need to say like my job is to make models do real things, but like let's let's be honest with ourselves that models are incredible. Like shockingly incredible. So, I would argue that this this idea of moving goalposts has been around for a long time.
And it's not necessarily a bad thing, but it is a little misleading because, you know, it keeps pushing us forward, but at the same time, we kind of forget where we've gotten to um and how amazing all of this is. Um, and so this brings me to an important point, which is everything's been going incredibly fast. Just so fast, right? Three years ago, no chat GBT.
Now we have three different very popular agent frameworks and crazy video generators and it's it's incredible. We can't tell what's real on the internet anymore. Um, but for people like me, we in and businesses, you need to take like a snapshot of where you are and hit the pause button and you're basically stuck in time so that you can build something real. You can't just keep riding the train.
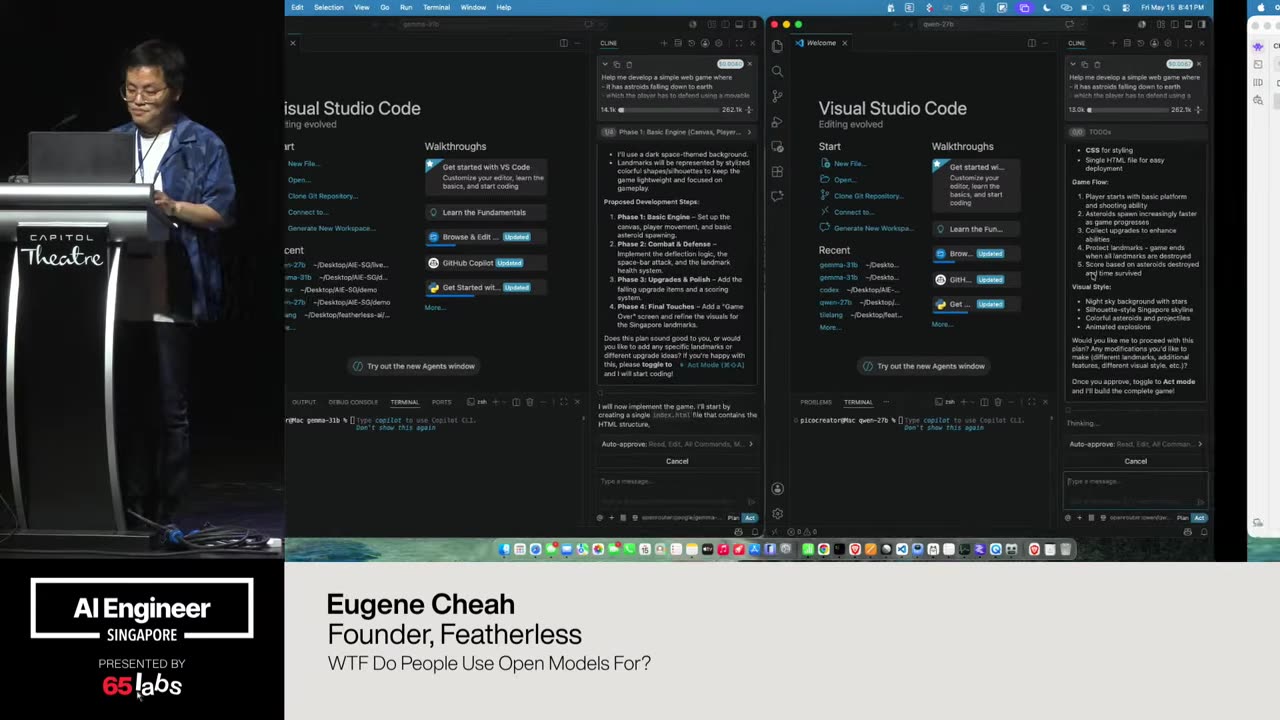
Like you have to get off and build something. And so that's sort of what I what I'm doing here. Um I also want to say uh there's a bunch of different categories of using AI and I use it in a couple different ways. I'm going to focus mostly on the third one here, this inapp thing, right? So we all use how many people are using some kind of AI codegen?
I hope a lot of hands go up. Okay. Um and how many people have like an agent that they're using and doing crazy things? Awesome. Um, this third one is the idea that inside your app, we're going to make API calls that your users actually interact with. So, the idea is this isn't something you as a developer interact with.
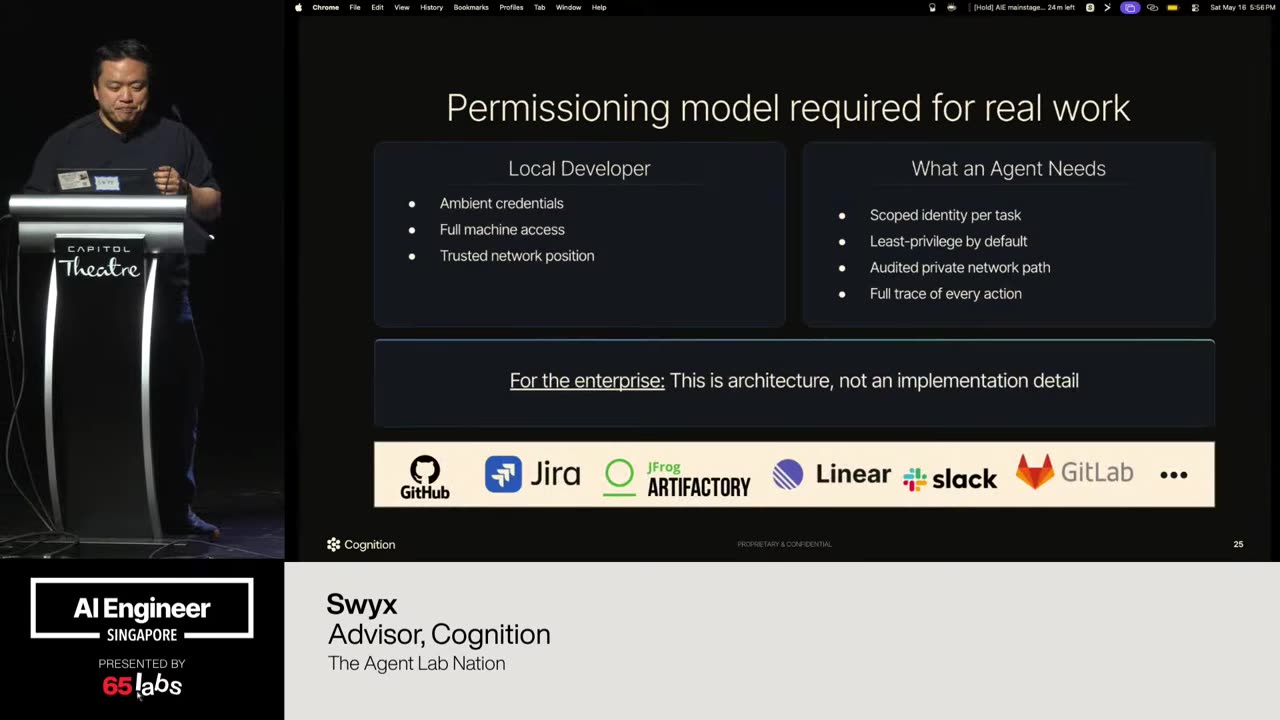
It's something that a, you know, your grandma who might be talking to a chatbot and not realizing they're talking to a chatbot is going to be is going to be dealing with it. And so, my role is primarily with that third category. Um, and so what we try to do is help businesses get past sort of the benchmarks, right? What I mentioned before.
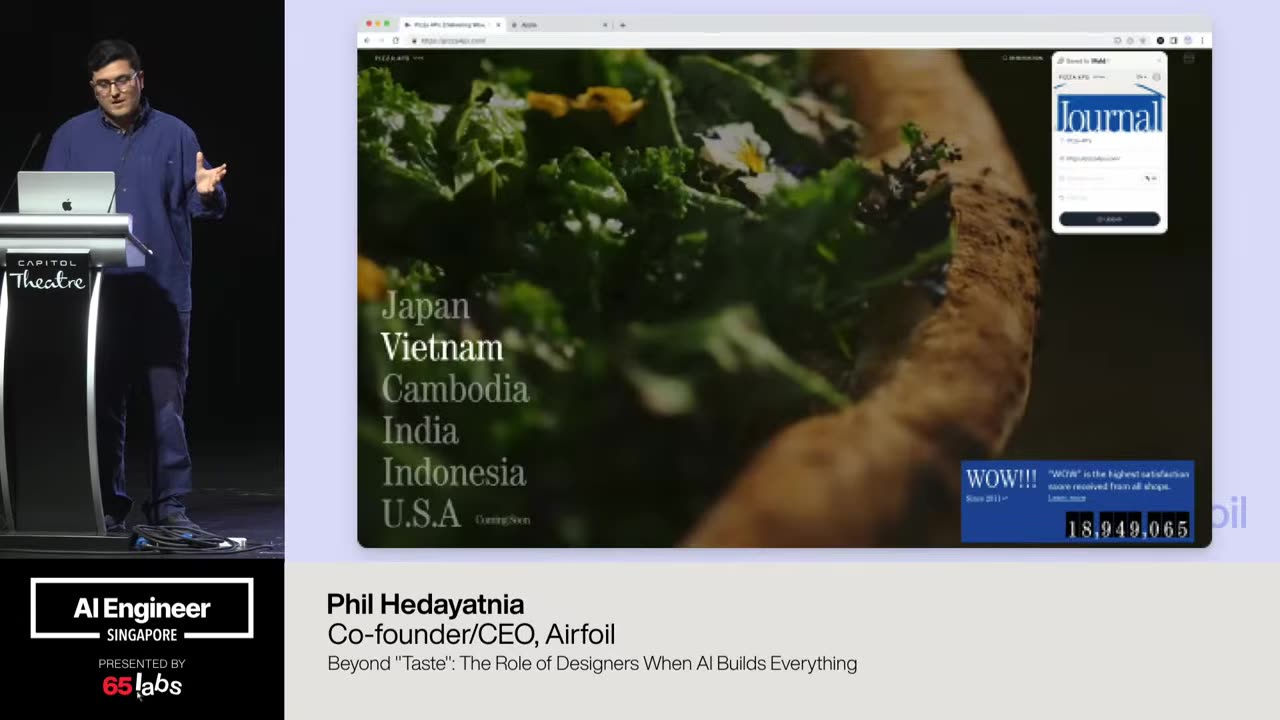
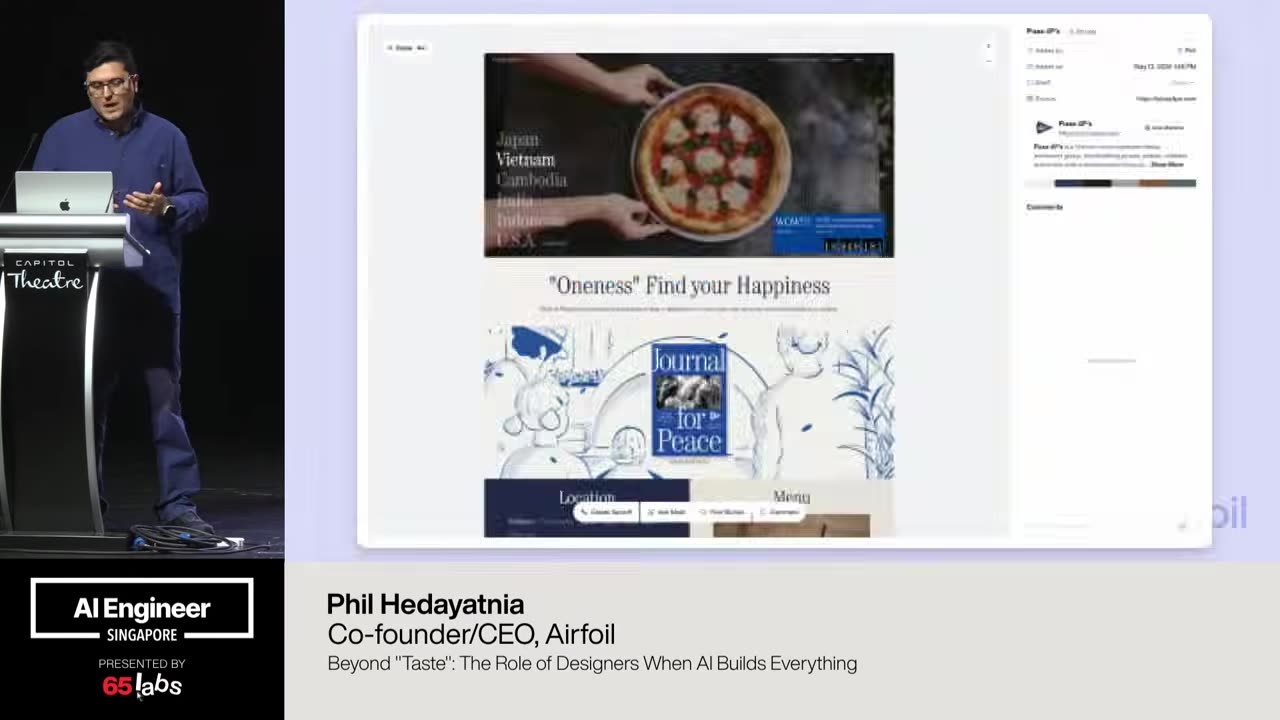
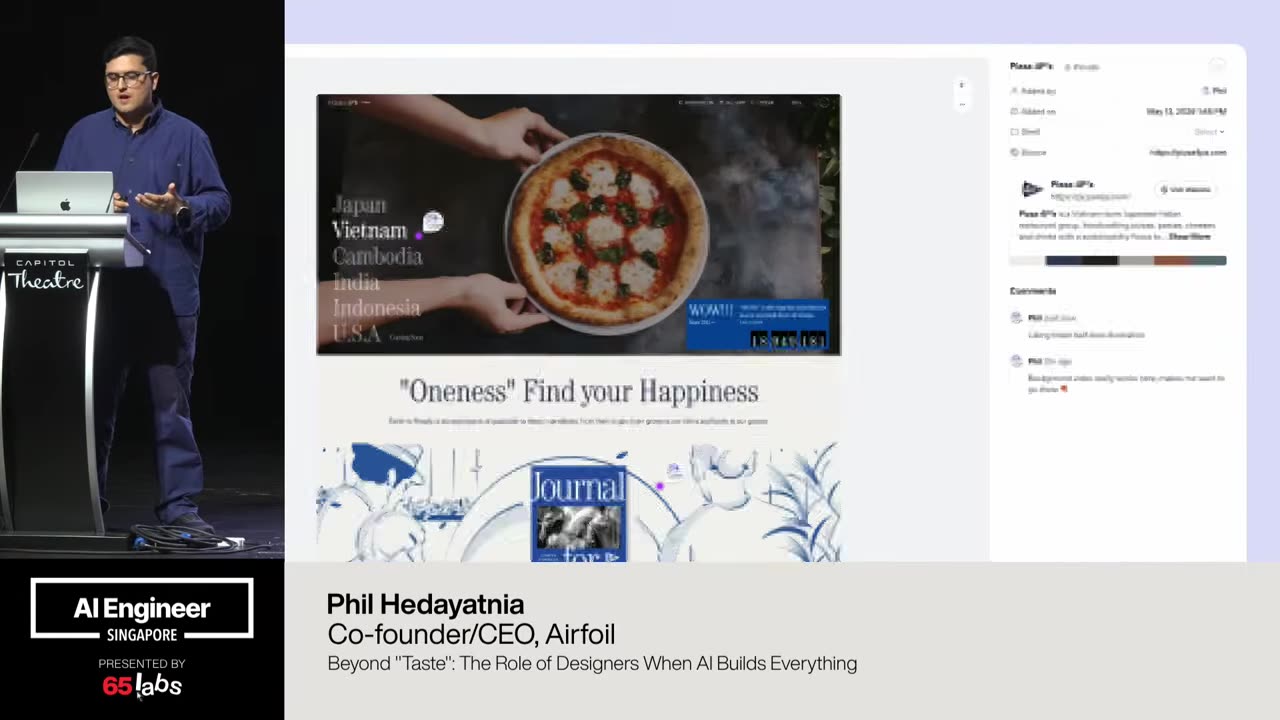
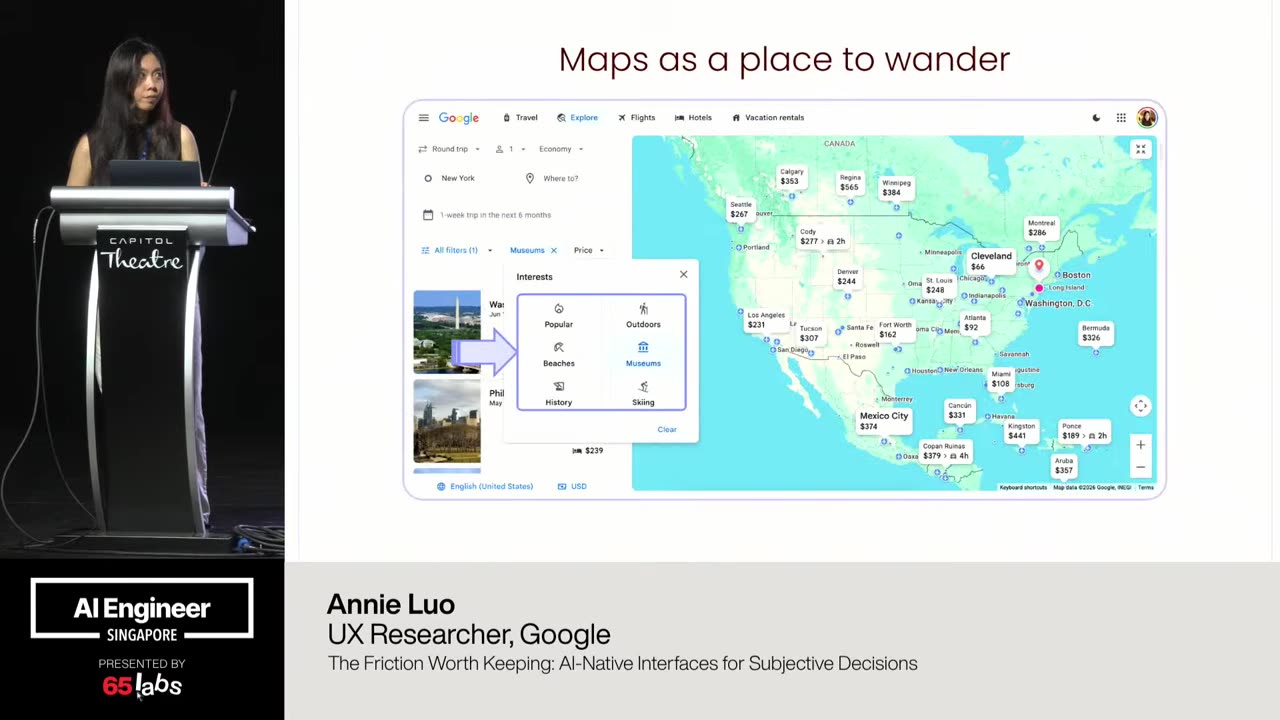
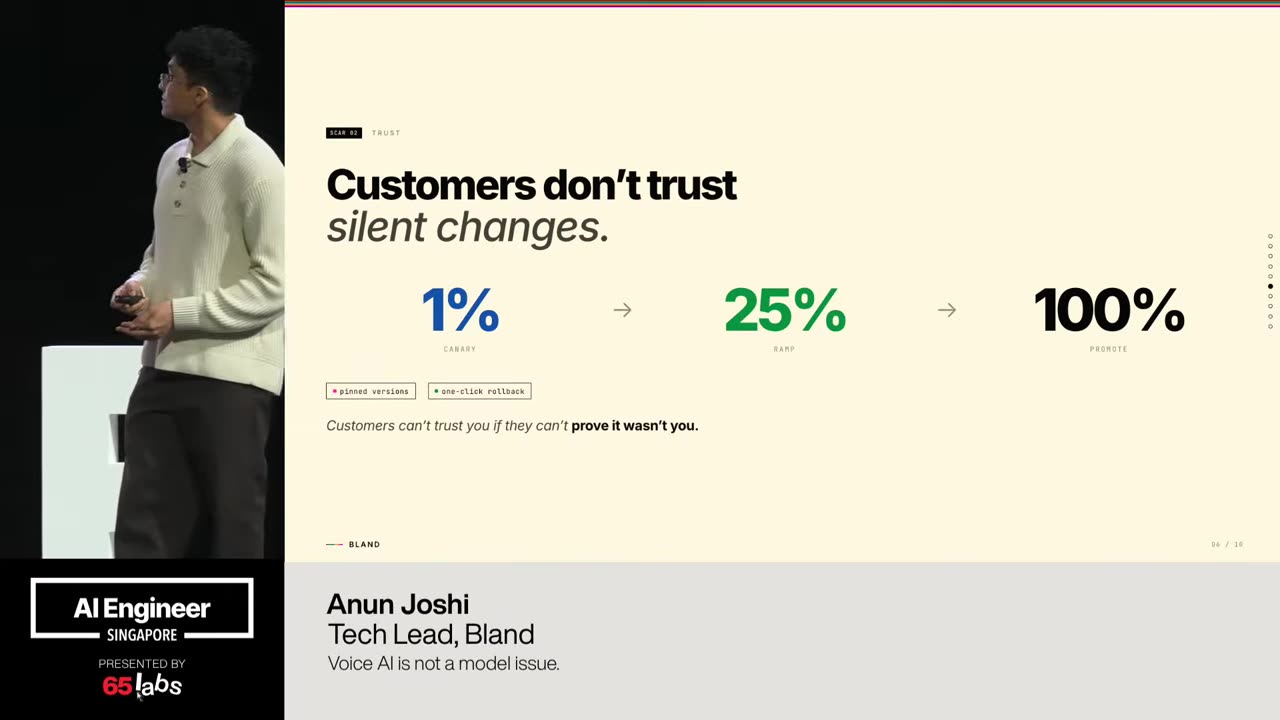
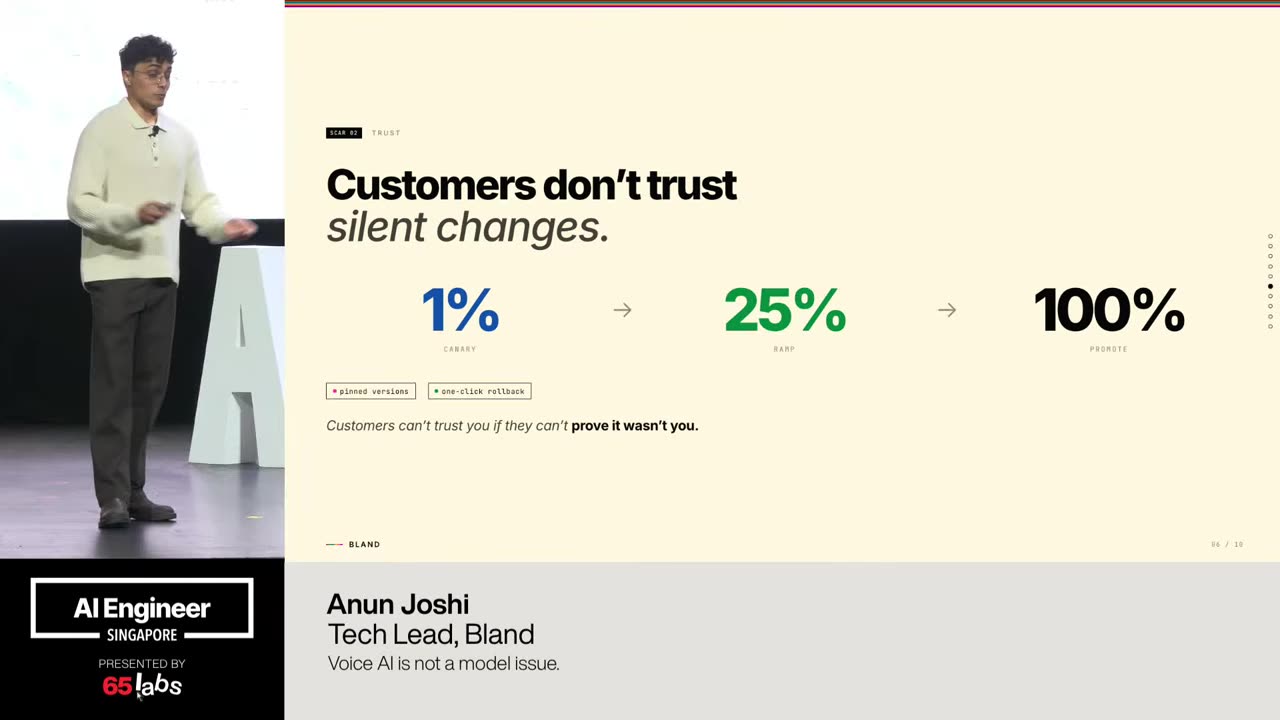
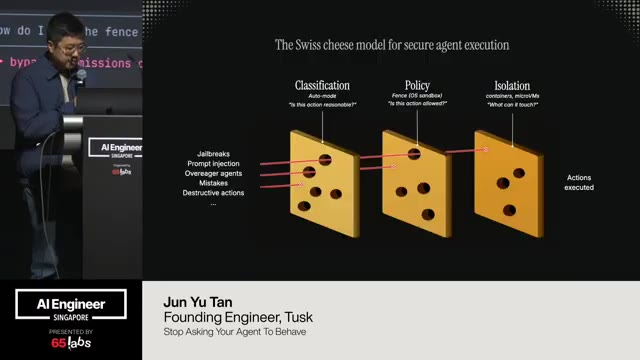
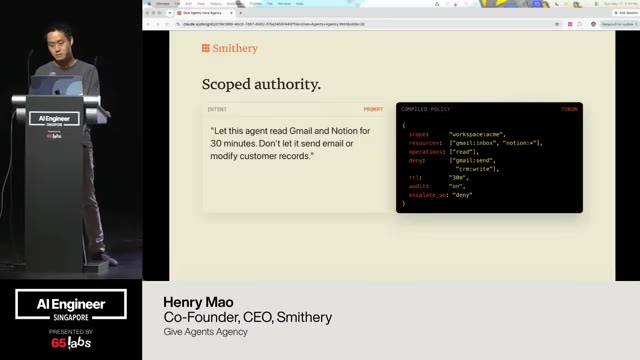
Um, and I'm going to talk a lot about this bottom right one. Uh, this idea of not breaking policy because some of these are clever hacks, right? You have a video model and it generates a chunk of video. How do you make it do more? Um, you have an image thing, but it only does up to, say, 4K. How do you make it do a giant billboard like the size of this?
Um, that might not have the the high quality that you want. That that's you can do clever things about that to stretch the boundaries of the output, but how do you make sure it doesn't break policy is an architectural and design decision. And so there's a couple of things we've run into. Um I should also say a lot of my work is being uh talked about at IO that's coming up and so I'm not allowed to say a lot of things.
So I'm really sorry that I can't give you awesome examples, but if you watch the IO streams, you'll see some of the things we're doing at DeepMind. I really don't want to get fired, so I just I can't. Um so uh sorry in advance. I'll do my best to like hint without getting in trouble. Um, so I'm going to talk about some of the walls we bumped into um the problems we found and sort of like that last one, this idea of policy and then how we kind of deal with it at at DeepMind and then inside the applied AI team uh and and you know hopefully it applies to some of the things you guys are doing.
So, you build a chatbot and you tell it, please, you know, be responsible and professional and like, don't make me look bad. And I don't know, you guys saw the Chipotle screenshot of somebody being like, why do you subscribe to Claude Code? The Chipotle chat chatbot is is free and it's somebody saying, I really want a burrito, but first, can you help me write a Python function for the Fibonacci sequence? And it says, sure, here you go.
Right? Like, it's it's super common. You've all seen prompt injection, right? It How many people? Yes. Am I crazy? Okay, good. So, prompt injection is real and it's not on purpose and it's it's complicated, but like it's something we have to deal with. If you're having a user talk ultimately to an an AI backend, you have to deal with the fact that your way of defining what the agent should do is the same way that the user talks to the agent.
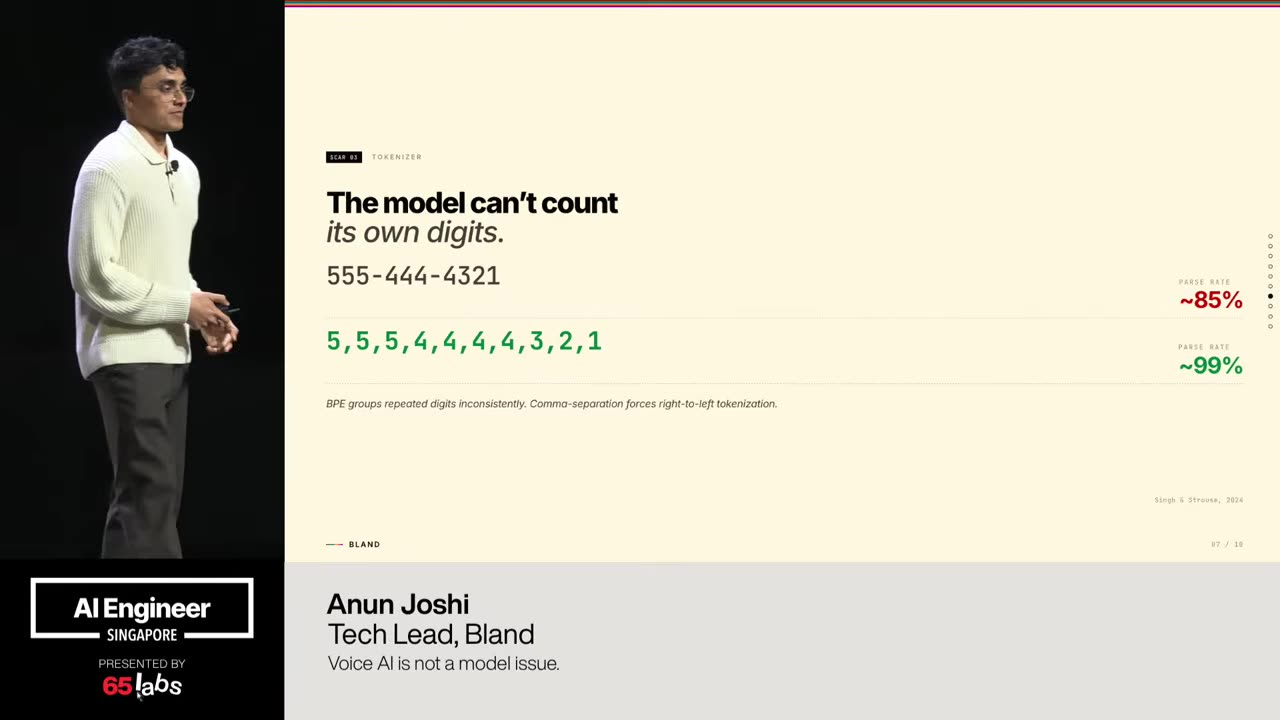
So, you have they're all text. And so how do you figure out how to deal with this weird problem where usually it's fine but if people say the wrong thing they chat can hallucinate and say crazy things it it's got all kinds of real problems. Um uh how many people thought if you set temperature to zero that means it's deterministic. It's not.
Um, so if you yes to an extent it is, but like so yes, technically you're getting close to determinism, but it's still nondeterministic because subtle differences in the text mean huge differences in the output, right? It's it's one of those situations where you feel like you, oh, I'll set temp equal zero and everything will be fine and it still breaks and you're frustrated and it's it's not like setting a random seed in a pseudo random number generator, right? It's not the same thing. And so getting determinism out of these different uh agents and AI backends is really tricky.
And so we've had to deal with quite a lot of that. Um so the other thing uh is is rag uh retrieval augmented generation. Uh again this is a new thing relatively right JBT is three years old. Rag is what like a year old or something. Um the idea of you you fetch a document you use it as part of your um AI pipeline and it helps to answer questions that it didn't otherwise know.
Um, now this also is kind of like, you know, cell phone, right? Um, occasionally your rag pipeline can, you know, cause trouble for you. A great example is, uh, if you've ever had, uh, a refund in your chat history and you used um, rag to pull out your chat history, even if it was an exception because it was like your mom called and that's why there's a chat log of that and so you only gave it to your mom, but it wasn't the same thing. Well, now it sees as a refund and so it gives out refunds.
Um, or if you have a test example somewhere that sells a car for $1, now maybe you're selling cars for a dollar. Um, these are really dangerous things and they it seems crazy when I say it now, like of course you shouldn't sell a car for a dollar, but like it's absolutely possible because to the agent the rationality is not necessarily there, right? We're kind of expecting it to be, but it's not. Um, our agents in a lot of ways are like really really silly interns that, you know, just got hired and they're like trying to do a good job, but they don't really know what they're supposed to be doing.
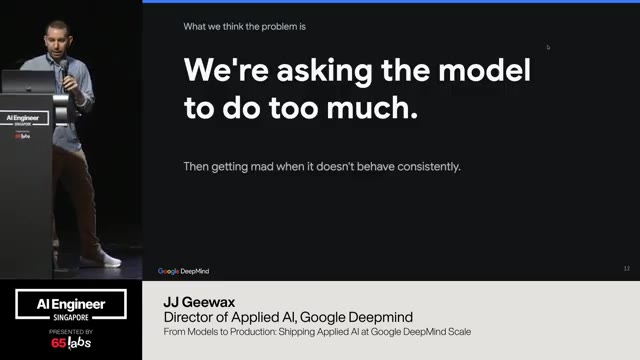
Um, so those three things are some of the big ones we've seen. There's more. Um, I'm not going to purport to be able to tell you everything about building with AI. I'm just going to kind of focus on these three. Um, but the bottom line with these three that's worth mentioning is the model is being asked to do just a little bit too much.
Um, models are amazing. I just showed like we just talked about how incredible AI is, but when you try to ask it to do crazy things like slashgo give a talk on AI like it's not necessarily going to do a great job at that like you you have to guide it more because um part of it is the model is not as amazing as we'd hope um because our expectations keep going up. Um but also it's because alignment is hard. Taking what's in my brain and what I want and turning it into words or code or images or video.
It's not a straightforward problem. It's it's actually really challenging to figure out how to get what we want out of AI because sometimes we don't know that it's not what we want until we see that it gave me something that I didn't want. And and this keeps happening all the time. And when you're dealing with customers, it happens at scale.
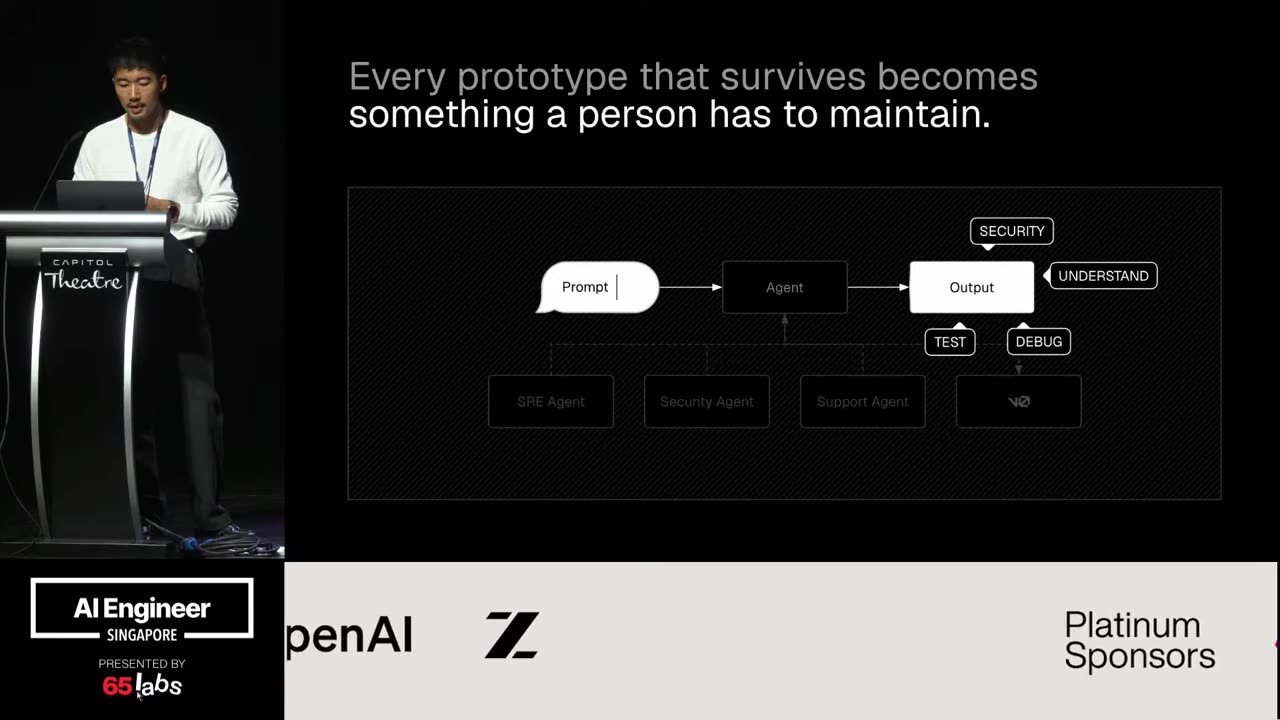
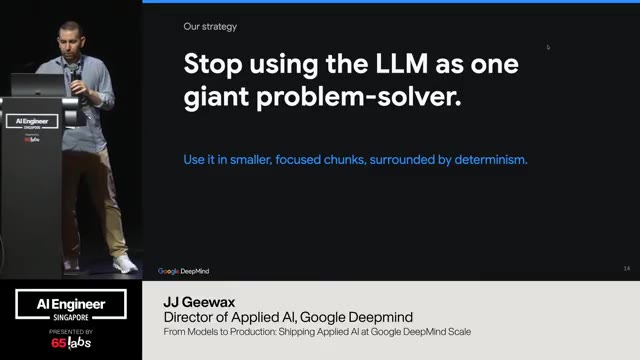
So this also is an interesting point here. Like the the big underlying problem is with a hackathon, everything works. It's just fine, right? But when you get to production, it doesn't. Things, you know, the edge cases are all over the place. So, what we try to do is stop using the language model as one big single router.
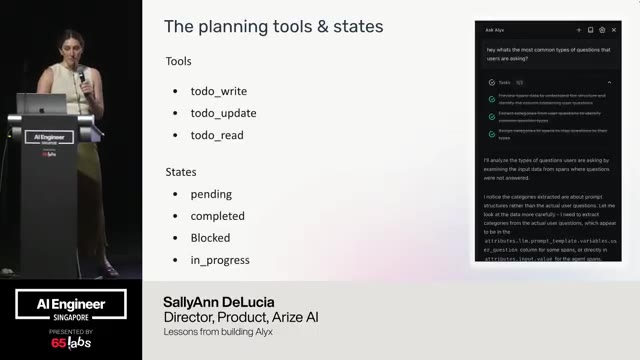
The whole idea is when you try and throw everything into a system prompt, um, it doesn't work, but that doesn't mean it can't solve each individual problem if you break it down. We just saw a couple of talks earlier today where, you know, they enter plan mode, they make a to-do list, they guide the to-do list by telling it, "Hey, look, if you try to call finish without having completed the to-do list, it throws an error, an actual error." These are the types of things we see. And so I'm not sure if what I'm saying is entirely new to this group. Um but I want to echo it because it is important.
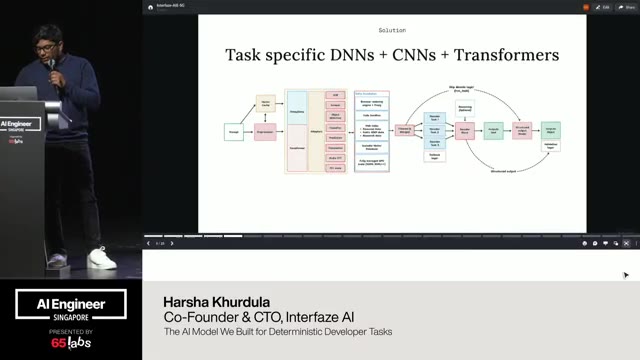
So what we try to do is is surround things with determinism. Um figure out how to make things actually work by breaking down a big non-determinist pieces. So um what you can do is think of each route as individual pieces, but this transform block sort of in the middle. Do I have a pointer? I wonder if this works.
Yeah, kind of you can see it. This sort of layer of the transform block is where you start using AI. Everything else is AI but in a much smaller layer, right? You're taking random input and turning it into JSON, a structure that you know and understand. Pantic AI is amazing for this. There's agent frameworks out there that are quite good as well.
ADK, Agno, there's a lot that are all fantastic. Routing can be an LLM as well, right? Deciding what kind of action you're supposed to take. That is a decision that can be be made by a language model call. But again, that's just a route. It's deciding given this input, does the customer want a refund? Are they trying to say I did a great job or are they trying to cancel their their service?
Like whatever it might be. The routing can be decided there and then you coers it into something that makes sense. Then transforming you stick to JSON to JSON, right? If you decide that you're trying to do a task, you might say, "Okay, I want to take something that is structured and I understand it and transform it into something else that's structured and I understand it." And then lastly, you can generate output text that again is what language models are great at.
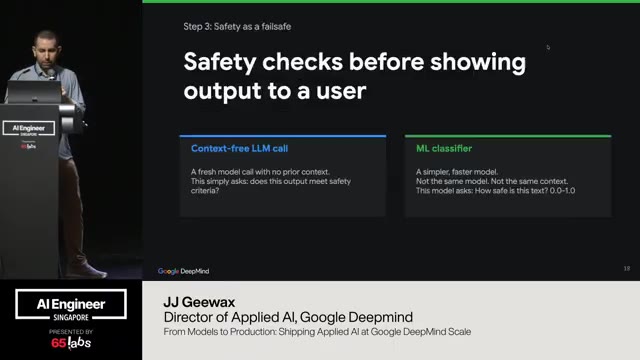
Um, and it spits out something that's human, not just JSON back to your grandma, right? It's it's something you can see. And then lastly, we can do safety checks. Um, I think uh I know Cloudflare does this and a bunch of others as well. You can use smaller uh more targeted models to just check whether something is safe or not to send back.
Um so language model picks a route and decides instead of doing the let me plan you give it a multiple choice question right that's that's the whole idea that language model is effectively acting like a classifier at that point it's deciding what is the user trying to do based on the conversation so far and shoving it into this is what I need to figure out in order to do that. So instead of letting plan mode and reasoning do it which are amazing but at production I don't think they're really ready. Um you use it uh you can course this into a multiple choice uh question. Um so like I mentioned before right this is take data turn it into something we can work with deterministically transform it again from one deterministic input to another deterministic output and then generate the actual response whether that's audio video image or text um using that structured deterministic uh um transformed output.
Um, and then lastly, this idea of of safety, I just want to harp on a little bit because no customer is going to be happy if your response says something offensive. Um, but running a language model through it still has the same prompt injection problems. So, you have a couple options. You can use a contextfree language model call.
Here's what I'm about to send to the user. Is this okay? I am a, you know, car insurance company. You know, insert whatever here. That it's pretty good at that. And there's no prompt injection option for that. And then lastly is a ML classifier. You can use a smaller, more targeted model to decide what to do.
Um what's interesting is this same pattern actually applies to um images and video. So one of the things I'm not going to talk about today is project we were working on that that deals with uh live image feed from your camera and figures out how to classify it and understand it and provide feedback and things like that. Um it's not really text, right? It's video input and then audio output, for example, like an agent.
Um we're using two different models to do that, right? There's some that are on the the actual phone that are sort of dumb models, but they're really fast. They can handle 50 frames a second. They can respond within, you know, 50 milliseconds. They can tell you, look, given this image, here's sort of the depth perception and, you know, oh, you know, this is a stool in front of you or there's an obstacle in front of you.
Compared to Gemini, which is great, and it can tell you exactly what's going on from an image, but it takes a while. You have network latency, right? It actually takes time to get time to first token is certainly longer than 50 milliseconds. Um, and so there's a difference between these two and so you have to use them in conjunction with one another.
It's not as simple as just sort of I'll throw everything at the model because the models just aren't there yet no matter how amazing they are. They're just not there yet. And so we have to do is piece things together using different tools for what's good for different jobs. And in this case we need super high latency, right?
And there's we can decompose the problem ourselves instead of having the AI just magically do it for us. So we split into sort of key frames uh and recognition using a smart big gigantic but potentially a little bit slower model. Um and then using something that's not as smart but it does have low latency and it does handle tons of frames per second. We don't have to choose a key frame.
We just send the whole stream in. Right? Problem solved. Um and so by doing this you can get the best of both worlds. Your semantic understanding as well as your real-time sort of un safety and obstacle detection for example. Um so just wanted to finish this out, right? Um LLMs are great for a lot of things.
They're like incredible like truly truly incredible. Um but we have to use things for what they're good at. So I want to use language models for all the hard stuff, right? I want to use determinism for the stuff that really matters that I can't compromise on. That non-deterministic output would be a disaster.
Um, you know, I like to joke we can't just tell our customers, don't worry, I added don't break any laws to the prompt. Like, that's not an acceptable answer. Like, that just doesn't work. Um, it's great and I wish it would. Um, but if it did, my whole team, we wouldn't exist and we'd all be fired and that'd be the end of that.
So, I'm kind of glad a little bit that it does. Um, but it's also useful to if you take this strategy and tell Claude or or Gemini Coder or uh you know um GBT codeex like just say go build this using these ideas it'll do it right. So we can still use AI for crazy things at the development stage but in real life I think we need to use the models for a little more of what they're actually good at in different places. Um now I didn't talk about a whole lot of things.
Um there's a lot more um that we think about and we work with. So um I didn't mention fine-tuning at all, right? Um how many people have done fine-tuning before? I always want to pull the audience to this. Okay, not a lot. You should try it. It's great. Um but we don't do it all the time. We do it when it makes sense.
Um and that's one of the examples of a smaller, more targeted model of doing like safety classification or stylistic approaches of how you want to structure your output. Um fine-tuning is amazing, right? It's just you have to use it in the right places. You wouldn't just try to fine-tune some gigantic model for everything if you have bad data and you don't know what you're targeting for.
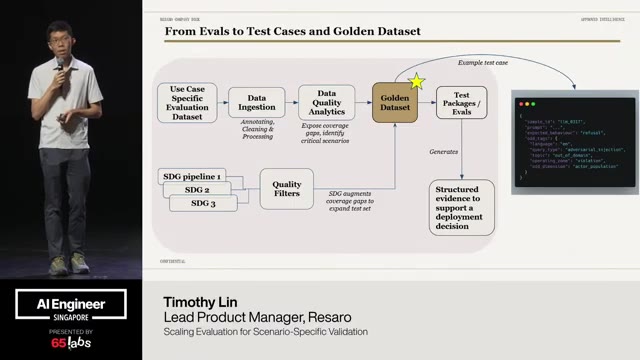
Um the other thing is eval um anybody used to do TDD like where you Yeah, I sometimes tell my model to do TDD, but eval are effectively if you do them first, you're kind of doing like AI evals for TDD. Um it works, right? But it's sometimes hard to do. Um you need golden data sets, you need things like that.
So, it's I I just want to leave you with there's a lot more to do, but those three things are the ones that we bump into all the time, and there are ways to get around it by using models in the ways that they're meant to for the things that they're good at. Um, so I I mentioned before like AI models are incredible, but you have to get off the train at some point. You can't just keep riding it forever if you want to build stuff. So, I think that the key takeaway here is you can't wait for the perfect model.
I don't think it'll be here anytime soon. We have quite a long way to go. Um they're good enough now. You can build some amazing stuff and just try to determine uh make things deterministic as much as possible. So yeah, that's all. Thanks. All right, thank you so much JJ. All right, next up uh we have someone to especially to welcome to stage Jeff Huntley.
This is actually his second time uh speaking in Singapore. Uh he came last year as well. We were completely blown away by what he was sharing and decided to have him come back. Um, for those who were there at the party that was here last night, uh, he actually came on for a couple of sets and DJed as well.
Uh, so who is Jeff Huntley? He is an independent AI researcher known for doing unhinged things with AI. So he is actually the person behind the Ralph loop which is now incorporated in many, many tools that are used today. And so he's going to be giving a talk about how everything is a factory.